

여기에서 무료 로 읽어보세요
Claude와 ChatGPT를 실제로 사용해 보셨다면 두 도구의 차이점을 느끼셨을 겁니다.
하나는 한 번의 대화로 20만 단어 분량의 문서를 처리할 수 있는 반면, 다른 하나는 약 12만 8천 단어까지만 처리할 수 있습니다.
또한 하나는 채팅에서 바로 인터랙티브 앱을 만들 수 있지만, 다른 하나는 그렇지 않습니다.
이러한 제약 조건과 기능은 실제로 업무 방식을 결정짓는 요소입니다.
어떤 도구를 사용할지 선택할 때 각각의 기능이 실제로 어떤 역할을 하는지 이해하는 것이 중요합니다.
1. 프로토타입, 프레젠테이션 및 디자인 자료 생성 (디자인 기술 불필요)
ChatGPT의 DALL-E처럼 사실적인 이미지를 생성하는 대신, Claude Design은 실행 가능한 디자인 자산을 생성합니다.
원하는 바를 설명해 주시면 클로드가 실제 프로토타입, 슬라이드 자료, 요약 자료 또는 프레젠테이션 목업을 제작해 드립니다.
직접 수정하거나 요청을 통해 디자인을 다듬을 수 있습니다.
디자인이 완성되면 Claude가 Claude Code에서 바로 구현할 수 있도록 디자인을 패키지로 묶어줍니다.
Canva, PDF, PowerPoint 또는 독립형 HTML 형식으로 내보낼 수도 있습니다.
이 도구는 창업자, 제품 관리자, 그리고 디자인 경험이 없더라도 아이디어를 시각화해야 하는 모든 사람을 위해 설계되었습니다.
ChatGPT는 보기 좋은 이미지를 생성하고, Claude Design은 바로
사용 가능한 목업을 생성합니다.
2. 채팅창을 나가지 않고 인터랙티브 앱을 구축하고 실행하세요
Claude에는 '아티팩트'라는 기능이 있습니다.
계산기, 데이터 시각화, 할 일 목록, 게임 또는 SVG 다이어그램과 같은 것을 만들도록 요청하면 코드 블록에 코드만 보여주는 것이 아닙니다.
실시간 미리보기 패널에서 빌드 과정을 보여주고 즉시 렌더링합니다.
즉시 작동하는 모습을 확인해 보세요
. 클로드에게 주택담보대출 계산기를 만들어 달라고 요청하면 몇 초 만에 미리보기 창에서 실제 작동하는 계산기를 사용할
수 있습니다.
계약금과 이자율을 조정하고 실시간으로 업데이트되는 수치를 확인할 수 있습니다.
수정하고 싶은 부분이 있으면 클로드에게 알려주세요.
앱을 다시 로드할 필요 없이 바로 눈앞에서 업데이트됩니다.
Claude에서는 React 컴포넌트, HTML 페이지, SVG 그래픽, Mermaid 다이어그램, 마크다운 문서 등이 모두 실시간으로 렌더링됩니다.
ChatGPT의 Canvas 도구도 개념적으로
유사하지만 실행 방식은 다릅니다 .
클로드의 실시간 렌더링과 직접적인 반복 작업 기능 덕분에 훨씬 즉각적인 결과물을 얻을 수 있습니다.
이러한 결과물을 링크로 게시하면 클로드 계정이나 API 키 없이도 누구나 접근할 수 있습니다.
필요한 인프라는 모두 제공됩니다.
3. 슬랙 워크스페이스에 직접 통합
클로드는 이제 슬랙에서 일합니다.
워크스페이스에 추가하면 팀원으로 표시됩니다.
사용 방법
다음과 같은 일을 할 수 있습니다:
- 연구, 글쓰기 또는 분석 관련 문의는 클로드에게 직접 메시지를 보내주세요.
- 게시글에 언급해 주세요
- 진행 중인 대화를 중단하지 않고 AI 비서 패널을 불러오세요.
Claude는 Slack 대화 내용을 읽고 답글을 작성한 후 공유하기 전에 검토할 수 있도록 해줍니다.
또한 Slack 채널과 파일을 검색하여 정보를 수집하고, 팀에서 논의한 내용을 종합하여 대화에서 실행 항목을 도출할 수 있습니다.
분산된 팀이나 Slack을 주로 사용하는 사람들에게는 이 기능이 매우 유용합니다.
다른 앱으로 전환하지 않고도 Claude의 도움을 받을 수 있기 때문입니다.
이 통합 기능은 워크스페이스 권한을 존중하며, 사용자가 볼 수 있도록 허용된 채널과 파일에만 접근합니다.
ChatGPT는 슬랙과의 기본 통합 기능을 제공하지 않습니다.
웹, 전화 및 API 통합을 통해 사용할 수 있지만, 슬랙 워크스페이스와의 내장 연결 기능은 없습니다.
4. 한 번의 대화로 20개의 파일을 업로드하고 분석하세요
Claude를 사용하면 대화당 최대 20개의 파일을 업로드할 수 있으며, 각 파일의 크기는 최대 30MB입니다.
PDF, Word 문서, 스프레드시트, 코드 파일 및 이미지를 여러 개 한 번에 업로드할 수 있습니다.
클로드
는 100페이지 미만의 PDF 파일에서 텍스트뿐만 아니라 차트, 표, 다이어그램과 같은 시각적 요소도 읽습니다.
단순히 텍스트만 읽는 것이 아니라 레이아웃에서도
의미를 추출합니다.
스프레드시트의 경우 구조와 관계를 분석합니다.
문서 간 분석
연구 논문 5편, 내부 보고서 3개, 데이터 세트 2개를 업로드하면 클로드가 이 모든 것을 하나의 대화에서 종합적으로 분석합니다.
다음과 같은 기능을 할 수 있습니다:
- 문서 간의 연결점을 찾아보세요
- 모순을 찾아내세요
- 통찰력을 종합하세요
ChatGPT는 파일 크기에 대해 관대한 편이지만(512MB), 클로드의 방식처럼 여러 문서를 한 번에 업로드하고 하나의 대화에서 여러 문서를 분석하는 것이 연구 중심적인 작업에 더 실용적입니다.
5. 대화 전반에 걸쳐 지속되는 지식 기반을 구축하세요.
Claude Projects는 AI 컨텍스트를 위한 폴더처럼 작동하는 워크스페이스 기능입니다.
작동 방식
특정 프로젝트를 생성하고 관련 문서를 업로드합니다.
회사 스타일 가이드, 제품 사양, 연구 논문, 코드 문서, 이전 결정 사항 등이 모두 지식 기반으로 저장됩니다.
클로드는 해당 프로젝트 내의 모든 대화에서 이 지식 기반을 자동으로 참조합니다.
매번 처음부터 다시 시작할 필요는 없습니다.
클로드는 프로젝트에 저장된 컨텍스트를 이미 알고 있습니다.
또한 프로젝트별로 사용자 지정 지침을 설정할 수 있으므로 클로드는 현재 작업 중인 프로젝트에 따라 어조, 초점 및 작업 가정을 조정합니다.
브라우저 프로필과의 차이점은 다음
과 같습니다.
이 기능은 브라우저 프로필 간 전환과 유사하게 작동하지만, Claude는 사용자의 문서 라이브러리, 스타일
기본 설정 및 각 프로필에 포함된 특정 지침을 기억합니다.
ChatGPT 프로젝트도 있지만 더 간단합니다.
클로드의 접근 방식은 편의 기능이라기보다는 실제 작업 공간 통합에 더 가깝습니다.
6. 답변하기 전에 추론 과정을 단계별로 보여드리겠습니다.
어려운 문제에 대해 심층적인 사고를 할 수 있도록 설정하면, 클로드는 체계적인 방식으로 문제를 해결해 나갑니다.
사고 과정을 보여주면서, 문제를 어떻게 세분화하고, 어떤 접근 방식을 고려했으며, 특정 경로를 왜 배제했는지, 그리고 어떤 부분이 불확실했는지 등을 확인할 수 있습니다.
마지막으로 최종 답을 제시합니다.
이는 더 빠른 응답을 받는 것과는 다릅니다.
응답 이유에 대한 투명성을 얻을 수 있습니다.
이는 수학 문제, 코딩 과제, 복잡한 연구 질문, 전략적 의사 결정 등 모든 분야에 중요합니다.
클로드가 증명 과정을 설명하거나 코딩 접근 방식을 개략적으로 설명할 때, 사고의 흐름을 따라가면서 문제가 되기 전에 오류를 발견할 수 있습니다.
7. 단순히 사람의 평가에만 의존하지 말고 원칙에 기반하여 훈련하세요.
이 요소는 눈에 잘 띄지는 않지만 클로드의 일상적인 행동 방식에 영향을 미칩니다.
ChatGPT는 인간 피드백 기반 강화 학습(RLHF)을 사용합니다.
수천 명의 사용자가 출력물을 평가하여 유용한 부분과 해로운 부분을 표시합니다.
모델은 이러한 평가를 통해 긍정적인 신호를 받는 행동을 생성하도록 학습합니다.
클로드는 헌법적 인공지능(CAI)을 사용합니다.
인간 평가자에 의존하는 대신, 앤트로픽은 헌법이라고 불리는 명확한 원칙 체계를 만들었습니다.
이 원칙들은 유엔 인권 선언과 같이 널리 인정받는 윤리적 기준에 기반을 두고 있습니다.
클로드는 이 헌법에 따라 자체 출력물을 평가하고, 헌법을 위반하는 요청은 거부하도록 훈련되었습니다.
실제로는 그 차이가 중요합니다.
RLHF는 모델에게 보상을 받기 위해 어떤 말을 해야 하는지를 가르칩니다.
반면, 컨스티튜셔널 AI는 모델에게 특정 출력이 왜 중요한지를 가르칩니다.
전자는 평점을 극대화하기 위한 규칙을 학습하는 것이고, 후자는 원칙을 학습하고 적용하는 것입니다.
이것이 바로 클로드가 어떤 영역에서는 덜 제약받는다고 느끼는 반면, 다른 영역에서는 더욱 의도적으로 신중하다고 느끼는 이유입니다.
안전 체계는 규칙 기반이 아닌 원칙 기반입니다.
따라서 임의적인 금지 조항이 적고, 특정 행위를 하는 이유와 하지 않는 이유에 대한 논리적인 근거가 더 많습니다.
8. 실제로 작동하고 실시간으로 실행되는 코드를 작성하세요.
클로드와 ChatGPT 모두 코드를 작성할 수 있습니다.
차이점은 안정성과 실행 속도에 있습니다.
코드 품질
개발자들은 클로드의 출력물이 재작성 횟수와 디버깅 시간을 줄여준다고 보고합니다.
클로드 역시 나쁜 코드를 만들긴 하지만, 기본 수준은 훨씬 높습니다.
실시간 실행이 중요합니다
실행 과정은 사람들이 생각하는 것보다 훨씬 중요합니다.
클로드의 코드를 에디터에 붙여넣으면 바로 실행되고, 출력 결과도 즉시 확인할 수 있습니다.
그리고 반복 작업을 통해 문제를 빠르게 파악하고 해결할 수 있습니다.
이처럼 빠른 피드백 루프를 통해 문제점을 발견하고 신속하게 수정할 수 있습니다.
ChatGPT의 코드 생성 기능은 강력하지만, 실행 결과를 즉시 미리 볼 수 없기 때문에 수동 테스트를 더 많이 해야 합니다.
이는 사용상의 불편함을 초래합니다.
이것이 당신에게 실제로 의미하는 바는 무엇일까요?
이 여덟 가지 역량은 여러분의 업무 방식을 결정짓습니다.
이는 단순한 마케팅 전략이나 차별화 요소가 아닙니다.
대용량 문서를 다루거나, 프로토타입을 제작하거나, 복잡한 문제에 대한 심층적인 추론이 필요한 경우, Claude는 ChatGPT에는 없는 도구를 제공합니다.
Slack을 주로 사용하고, 프로젝트 기반의 컨텍스트에서 작업하거나, AI의 사고 과정을 투명하게 파악하고 싶다면 Claude가 최적의 선택입니다.
ChatGPT는 이미지 생성, 웹 검색, 더 폭넓은 플러그인 생태계, 메모리 관리 기능 등 여러 장점을 가지고 있습니다.
하지만 어느 쪽이 무조건 더 낫다고 할 수는 없습니다.
결국 중요한 것은 실제 작업 흐름에 무엇이 필요한가입니다.
대부분의 사람들은 둘 중 하나만 사용해도 충분합니다.
어떤 사람들은 다른 작업을 위해 둘 다 필요하다고 느끼기도 합니다.
이는 지극히 당연한 일입니다.
중요한 것은 마케팅 문구나 막연한 인상에 의존하는 대신, 각각의 기능이 실제로 어떤 것인지 정확히 아는 것입니다.
직접 기능을 사용해 보세요.
Claude's Artifacts에서 무언가를 만들어 보세요.
대용량 문서를 업로드해 보세요.
어려운 문제에 대해 심층적인 사고를 해보세요.
사용 경험이 어떻게 달라지는지 확인해 보세요.
이러한 기능들이 여러분의 업무에 얼마나 중요한지 금방 알 수 있을 겁니다.
그게 바로 진짜 중요한 거죠.
클로드의 사용 한도에 다시는 걸리지 않는 방법
여기에서 무료 로 읽어보세요
당신은 글쓰기 프로젝트를 진행 중입니다.
클로드와 함께 약 30분 동안 작업을 해왔죠. 새로운 주제를 보내자 "사용 횟수 제한에 도달했습니다.
내일 다시 시도해 주세요.
"라는 메시지가 뜹니다.
이미 돈을 지불했고, 오늘 할 일은 끝났다는 것을요.
답답한 마음은 충분히 이해합니다.
하지만 대부분의 사람들이 모르는 사실이 하나 있습니다.
클로드는 여러분의 토큰을 먹어치우는 게 아닙니다.
귀하의 워크플로는 다음과 같습니다.
이러한 현상이 발생하는 이유 이해하기
해결책을 찾기 전에 Claude가 작동하는 방식에 대해 한 가지를 이해해야 합니다.
이 한 가지를 이해하면 모든 것이 달라집니다.
클로드는 당신과의 대화를 기억하지 못합니다.
메시지를 보낼 때마다 클로드는 대화 내용을 처음부터 다시 읽습니다.
첫 번째 메시지는 거의 비용이 들지 않습니다.
두 번째 메시지는 어떨까요? 클로드는 새로운 질문을 생각하기도 전에 첫 번째 메시지와 그에 대한 답글을 모두 처리합니다.
서른 번째 메시지를 보낼 때는 모델이 이전 29개의 대화와 모든 답글, 그리고 사용자가 업로드한 파일까지 모두 다시 읽습니다.
이것은 결함이 아닙니다.
모든 언어 모델이 작동하는 방식입니다.
하지만 이는 대화 규모가 커질수록 보내는 모든 메시지의 비용이 점점 더 높아진다는 것을 의미합니다.
최근 이러한 행동을 추적한 한 개발자는 토큰 사용량의 약 98.5%가 단순히 대화 기록을 다시 읽는 데 사용되고, 실제 새로운 작업은 1.5%에 불과하다는 사실을 발견했습니다.
이것이 바로 장시간 세션을 진행하면 할당량이 빠르게 소진되는 이유입니다.
이렇게 생각해 보세요.
한 번의 교환에 1단위가 소모됩니다.두 번의 교환에 총 4 유닛이 소모됩니다.
세 번의 교환에 6 유닛이 소모됩니다.
4번의 교환에 8 유닛이 소모됩니다.
30통의 메시지를 주고받았다고 해서 비용이 30배로 늘어나는 건 아닙니다.
모든 대화 내용에 이전 대화 내용이 모두 포함되기 때문에 훨씬 더 많은 비용을 지불하게
되는 겁니다.
방법 1: Claude 사용 방식을 최적화하세요
15~20통의 메시지를 주고받을 때마다 새로운 채팅을 시작하세요.
긴 대화는 시간 낭비입니다.
대화가 길어질수록 클로드가 전달해야 할 맥락이 많아지기 때문입니다.
클로드에게 모든 내용을 요약해달라고 요청하고, 그 요약본을 복사해서 새 채팅방을 열고 첫 메시지로 붙여넣으세요.
이렇게 하면 대화의 연속성을 유지하면서 불필요한 부분을 제거할 수 있습니다.
후속 조치를 취하는 대신 수정하세요.
클로드가 실수를 했을 때, 바로 수정 메시지를 보내지 마세요.
원래 메시지에서 '편집'을 클릭하고 수정 후 다시 생성하세요.
이전 대화 내용은 누적되지 않고 새 메시지로 대체됩니다.
보내는 모든 메시지는 대화 기록에 추가되며, 클로드는 매 턴마다 모든 메시지를 다시 읽습니다.
따라서 서른 번째 메시지쯤 되면, 한 번의 대화에 소모되는 토큰은 첫 번째 대화보다 서른한 배 더 많아집니다.
설정을 메모리에 저장하세요.
"저는 마케터이고, 편안한 어조로 글을 씁니다.
"로 시작하는 모든 대화는 이전에 이미 설정한 값에 대해 토큰을 소모합니다.
클로드의 메모리 기능은 이 문제를 영구적으로 해결합니다.
설정 > 기능 > 메모리로 이동하여 클로드에게 원하는 설정을 한 번만 알려주세요.
그러면 이후 모든 대화에 자동으로 설정이 적용됩니다.
꼭 필요한 경우가 아니면 Opus 대신 Sonnet을 사용하십시오.
Opus는 Sonnet보다 대략 두 배의 토큰을 소모합니다.
모든 작업에 심도 있는 추론 능력이 필요하지 않다면 Sonnet을 사용하는 것이 좋습니다.
Opus는 정말 중요한 순간을 위해 아껴두세요.
설정에서 사용량을 확인하세요.
Pro 및 Max 사용자는 설정 > 사용량으로 이동하여 5시간 세션 및 주간 사용량 한도 진행률을 확인할 수 있습니다.
정기적으로 확인하여 사용량 현황을 파악하세요.
이 모든 것은 새로운 구독을 필요로 하지 않습니다.
단지 더 스마트한 습관을 들이는 것일 뿐입니다.
이러한 습관들을 몸에 익히면 한계가 더 이상 벽처럼 느껴지지 않을 것입니다.
방법 2: 요청을 일괄 처리하고 프로젝트를 활용하세요
이 접근 방식에는 실제로 두 가지 부분이 있으며, 이 두 부분은 함께 작동합니다.
먼저, 요청들을 일괄 처리하세요.
다음과 같이 개별 메시지를 보내는 대신:
이 기사의 내용을 요약하시오.
답변 -
주요 내용을 글머리 기호로 나열하세요.
답변 —
제목을 제안해 주세요.답변 -
다음과 같은 메시지를 하나 보내세요:
이 기사를 요약하고, 주요 내용을 목록으로 정리한 후, 제목을 제안해 보세요.
메시지 하나, 답변 세 개, 컨텍스트 로드 한 번. 게다가 클로드는 전체적인 상황을 한눈에 파악하기 때문에 답변의 질도 더 높은 경우가 많습니다.
둘째, 유료 플랜을 사용 중이라면 Claude Projects를 활용하세요.
프로젝트는 대부분의 사용자가 알고는 있지만 실제로 사용하는 경우는 드문 기능입니다.
이 기능은 특정 문제를 해결해 줍니다.
파일을 한 번만 업로드하면 Claude가 토큰을 다시 계산하지 않고도 여러 대화에서 해당 파일을 참조할 수 있습니다.
장기간에 걸친 글쓰기 프로젝트를 진행한다고 상상해 보세요.
스타일 가이드, 브랜드 가이드라인, 그리고 이전 작업물을 업로드합니다.
일반적인 대화에서는 이러한 파일을 참조할 때마다 파일을 다시 처리해야 합니다.
하지만 프로젝트를 사용하면 이러한 파일들이 캐시됩니다.
따라서 동일한 문서를 반복적으로 사용하더라도 메시지 처리 속도가 훨씬 빨라집니다.
프로젝트 파일은 최대 30MB까지 저장할 수 있으며, 파일 수는 무제한입니다.
따라서 진정한 지식 기반을 구축할 수 있습니다.
바로 이 점에서 클로드는 단순한 챗봇이 아니라 사용자의 상황을 진정으로 이해하는 조력자처럼 기능합니다.
방법 3: 프롬프트 최적화 | Claude의 배치 API.
대부분의 기술 사용자들이 실질적인 비용 절감을 경험하는 부분이 바로 이 지점이지만, 그 원칙은 누구에게나 적용됩니다.
출력 토큰은 입력 토큰보다 5배 더 비쌉니다.
굳이 그렇게 길 필요가 없는 500단어짜리 답변 하나만으로도 상당한 토큰이 낭비될 수 있습니다.
그러니 클로드에게 무언가를 요청할 때는 구체적으로 작성하세요.
"이것을 더 좋게 만들어 보세요.
" 대신에다음과 같이 해보세요: 이 섹션의 가독성을 최적화하세요.
반복되는 상수를 추출하고 오류 처리를 추가하세요.
두 번째 프롬프트는 클로드가 당신이 원하는 바를 정확히 알고 있기 때문에 추가 설명에 필요한 토큰 낭비를 줄여줍니다.
결과적으로 더 빠르게 원하는 결과를 얻고 토큰 사용량도 줄어듭니다.
반복적인 프로세스나 자동화를 실행하는 사람들에게는 훨씬 더 강력한 기능이 있습니다.
클로드의 배치 API.
배치 API를 사용하면 수백 또는 수천 개의 요청을 한 번에 보낼 수 있습니다.
Claude는 이러한 요청을 효율적으로 처리하고 정상 가격의 50%만 청구합니다.
단일 배치 처리 작업은
최대 1시간이 소요될 수 있지만, 급하지 않다면 상당한 비용 절감 효과를 볼 수 있습니다.
많은 팀들이 일괄 처리와 또 다른 기술인 프롬프트 캐싱을 결합하여 토큰 비용을 60% 이상 절감했습니다.
프롬프트 캐싱을 사용하면 시스템 지침이나 대용량 참조 문서와 같이 프롬프트의 일부를 캐시할 수 있도록 표시할 수 있습니다.
시간 범위 내에서 동일한 캐시된 콘텐츠를 후속 요청에서 사용하는 경우 해당 토큰에 대해 정상 비용의 10%만 지불하면 됩니다.
예를 들어, 2,000단어 분량의 시스템 프롬프트를 시간당 10번 호출하는 경우, 정상 가격으로 약 18,000개의 토큰을 절약하고 캐시된 토큰으로 대체하여 90% 할인된 가격으로
사용할 수 있습니다.
이 방법은 API를 통해 Claude를 사용할 때 가장 유용하지만, 원칙 자체는 이해해 둘 가치가 있습니다.
재사용 가능한 컨텍스트를 작게 유지하고 깔끔하게 참조하는 것이 중요합니다.
모든 것을 바꾸는 것은 무엇일까요?
이 세 가지 방법에는 한 가지 공통점이 있습니다.
바로 더 많은 돈을 지불하거나 더 높은 등급의 요금제를 구매하는 것이 아니라, 클로드의 실제 작업 방식에 맞춰 워크플로를 바꾸는 것입니다.
대부분의 사람들이 사용량 제한에 도달하는 이유는 다음과 같습니다.
하지만 클로드는 다르게 설계되었습니다.
짧고 집중적인 작업, 명확하게 정의된 요청, 새로운 맥락에 맞춰 설계되었습니다.
이것을 이해하고 나면, 한계는 더 이상 임의적인 것처럼 느껴지지 않습니다.
예측 가능한 것처럼 느껴지죠. 그리고 예측 가능한 것처럼 느껴지면 관리할 수 있게 됩니다.
12개 메시지만 보내고도 메시지 제한에 걸렸다고 불평하는 사람은 아마도 하나의 대화를 계속 이어가면서 여러 개의 후속 메시지를 보냈을 가능성이 큽니다.
메시지 제한에 걸린 적이 없는 사람은 처음부터 다시 시작하는 것이 제한이 아니라 장점이라는 것을 이해하고 있습니다.
대화 기록은 생각만큼 도움이 되지 않습니다.
대부분 불필요한 작업량일 뿐입니다.
워크플로에서 대화 기록을 제거하기 시작하면 업무 효율성이 크게 향상되는 것을 확인할 수 있습니다.
이 과정은 당신의 본모습을 바꾸거나 업무의 질을 떨어뜨릴 필요가 없습니다.
단지 클로드의 작동 방식에 저항하는 대신, 클로드의 원리에 맞춰 협력하면 됩니다.
이것이 바로 진정으로 중요한 변화입니다.
클로드의 스킬 100가지를 모두 사용해 봤습니다.
이것들이 최고입니다

여기를 클릭하시면 제 무료 클로드 강좌 ( 20개 이상의 강의)
클로드에게 프레젠테이션 제작을 의뢰했는데 2010년도 학교 과제처럼 보이는 결과물을 받았다면, 당신만 그런 게 아닙니다.

스킬 없이 클로드를 사용하면 이렇게 됩니다.
같은 프롬프트를 사용하되, 앤트로픽의 브랜드 가이드라인을 준수하는 스킬을 활용했을 때 얻은 결과입니다.
색감, 디자인, 모든 게 완벽했어요!

그게 바로 기술이 만들어내는 차이입니다.
이처럼 스킬을 활용하면 맞춤형 워크플로우를 만들고, 반복적인 작업에 소요되는 시간을 절약하고, 회사 브랜드 가이드라인, 차트 스타일, 글꼴 선택, 시각 디자인 원칙 등을 준수하는 콘텐츠를 생성할 수 있습니다.
제가 인터넷을 샅샅이 뒤져 최고의 클로드 스킬을 찾아냈습니다 (여러분은 그럴 필요가 없어요). 이 가이드에서는 다음 내용을 살펴보겠습니다.
- 클로드 스킬 사용 방법
- 클로드(Claude)가 가진 최고의 11가지 스킬 (프레젠테이션, 마케팅, 비즈니스 등)
- 클로드 스킬을 빠르게 설치하는 방법
클로드 스킬 사용 방법
스킬 기능을 사용하려면 먼저 이 기능을 활성화해야 합니다.
설정 → 기능 → 스킬 켜기를 선택하세요.

스킬을 만드는 데 기술적인 지식이 필요한 것은 아닙니다.
Claude에는 스킬을 자동으로 만들어주는 내장 스킬 생성기가 있습니다.
스킬 생성기를 활성화하는 방법은 다음과 같습니다.
- 왼쪽 사이드바의 환경설정으로 이동하세요.
- "기술"을 클릭하세요
- “스킬 크리에이터”를 선택하세요
- 스킬 생성기 기능을 켜세요(항상 켜짐 상태로 유지).

스킬 섹션에서는 Anthropic이 만든 스킬을 볼 수 있습니다.
스킬 브랜드 가이드라인을 활성화하고 아래 프롬프트를 입력하면 Anthropic의 색상, 디자인 등이 적용된 슬라이드를 볼 수 있습니다(이전에 보여드린 예시와 같습니다).

클로드의 역량에 대한 간단한 프레젠테이션을 만드세요.
앤트로픽 브랜드 가이드라인을 활용하세요.
기술을 사용하는 방법에는 두 가지가 있습니다.
점 세 개를 클릭하고 "채팅에서 시도"를 선택하거나, 클로드가 어떤 스킬을 사용할지 알아서 판단하도록 둘 수 있습니다.
제 경험상 클로드는 요청에 맞는 스킬을 꽤 잘 찾아줍니다.
다만, 설치된 각 스킬의 기능을 정확히 알고 있어야 적절한 스킬을 사용하여 요청을 보낼
수 있습니다.
클로드가 올바른 기술을 선택했는지 확인하려면 답변의 첫 부분을 읽어보세요.

꿀팁: 코워크 채팅을 재사용 가능한 스킬로 만들 수 있습니다.
채팅 이름 옆의 드롭다운 화살표를 클릭하고 "스킬로 변환"을 선택하세요.
여기를 클릭하여 제 무료 클로드 강좌 ( 20개 이상의 강의)
를 받으세요 📝 클로드가 당신처럼 글을 쓰도록 만드는 최고의 방법
클로드의 최고의 기술들
세상에는 다양한 기술들이 있습니다.
제가 찾은 최고의 기술들을 소개합니다.
프레젠테이션 및 시각 자료 제작 기술
1) 슬라이드 데크 빌더
문제:
프레젠테이션을 준비하는 데 필요 이상으로 시간이 오래 걸립니다.
속도를 늦추는 것은 디자인이 아닙니다.
문제는 그 전에 해야 할 모든 일, 즉 무슨 말을 해야 할지, 어떤 내용을 어떤 순서로 말해야 할지, 어떤 내용을 따로 슬라이드에 넣어야 할지, 어떤 내용에 더 자세한 설명이 필요한지 등을 생각하는 데 있습니다.
바로 그 부분에서 시간이 많이 소모됩니다.
텅 빈 슬라이드를 멍하니
바라보고 있으면 어느새 한 시간이 훌쩍 지나가 버립니다.
기술:
대략적인 아이디어(몇 문장, 주제 등)만 제공하면 됩니다.
그러면 프로그램이 그 아이디어를 바탕으로 이미 의미가 정리된 슬라이드 시퀀스를 만들어주고, 설정한 시각적 스타일을 적용하여 실제 초안을 제공합니다.
작동 원리:
이 방법은 시간을 낭비하게 만드는 두 가지 과정, 즉 구조를 구상하고 형태를 갖추는 과정을 건너뜁니다.
완전히 새로운 것에서 시작하는 대신, 이미 형태를 갖춘 것을 개선하는 것부터 시작하는 것입니다.

링크: 튜토리얼 보기 | 스킬 다운로드
2) 설명 그래픽
문제:
어떤 주제들은 읽어도 와닿지 않을 때가 있다.
설명을 전부 듣고 끝까지 읽었는데도… 뭔가 제대로 이해가 안 돼요.
그래서 다시 읽고, 또 다시 읽고…
기술:
말로만 설명하기 어려운 개념이라도 입력해 보세요.
그러면 이 프로그램은 간단한 비유, 시각적인 단계, 따라하기 쉬운 짧은 섹션으로 구성된 HTML 설명 영상을 만들어 줍니다.
작동 원리:
때로는 형식을 바꾸는 것, 즉 텍스트로만 가득 찬 방식에서 시각적인 안내 방식으로 바꾸는 것만으로도 충분합니다.
같은 개념이지만 완전히 다른 경험을 제공할 수 있습니다.

링크: 튜토리얼 보기 | 스킬 다운로드
인공지능이 당신처럼 글을 쓰도록 만드는 가장 좋은 방법
.md 파일 하나만 있으면 글쓰는 방법을 배우기에 충분합니다.
마케터와 사업주를 위한 스킬
3) 브랜드 캐러셀 생성기
문제:
아이디어를 소셜 미디어 콘텐츠로 만드는 것과, 그 콘텐츠를 브랜드 이미지에 맞게 실제로 구현하는 것은 완전히 다른 문제입니다.
대부분의 사람들은 두 가지 좋지 않은 선택지 사이에서 딜레마에 빠지게 됩니다.
하나는 어색한 느낌의 일반적인 템플릿을 재사용하는 것이고, 다른 하나는 일관성 있게 보이도록 모든 게시물을 수정하는 데 너무 많은 시간을 쏟는 것입니다.
기술:
이 기능은 사용자의 콘텐츠를 브랜드 캐러셀로 변환해 줍니다.
단순히 슬라이드로 나뉜 일반적인 게시물이 아닙니다.
여러분의 자료를 중심으로 구성된 캐러셀 형태로, 실제로 게시할 만한 스타일로 디자인되어 다음 주에 다시 게시하더라도 처음부터 다시 만들 필요가 없습니다.

링크: 스킬 다운로드 | 스킬 다운로드
4) 브랜드 도포기
문제:
문서 작성을 마치면 기술적으로는 완료된 것입니다.
글 자체는 괜찮고, 구성도 괜찮다.
하지만 뭔가 여전히 어색하다.
브랜딩이 문제다.
글꼴도 잘못됐고, 색상도 어울리지 않고, 로고도 없다.
완성된 디자인인데도 초안처럼 보인다.
기술:
브랜드 규칙(글꼴, 색상, 로고)을 입력하면 해당 규칙이 문서에 자동으로 적용됩니다.
결과물이 다른 사업 자산과 일관성 있게 보입니다.
마감일 전에 급하게 만든 것처럼 보이지 않아요.
작동 원리:
대부분의 사람들은 이 부분을 마지막에 처리합니다.
그리고는 서둘러 끝내거나, 건너뛰거나, 아니면 안에 있는 내용만큼 완성도가 높지 않은 결과물을 보내곤 합니다.
이 서비스는 마지막 단계, 즉 최종 결과물을 완성하는 과정을 대신 처리해 줍니다.
생각이나 글쓰기는 필요 없습니다.
단지 작업 초안이 아닌 실제 결과물처럼 느껴지도록 만들어주는 부분만 담당합니다.

링크: 튜토리얼 보기 | 가이드 읽기 | 스킬 다운로드
5) 시장 경쟁업체
문제:
경쟁사 조사 결과는 대개 비슷합니다.
책 몇 페이지를 훑어보고 몇 가지 패턴을 발견하고 어딘가에 뭔가를 적어두지만, 그 내용을 실제로 활용할 수 있는 것으로 바꾸지 않고 그냥 넘어가 버리는 경우가 많습니다.
연구는 진행되었지만, 유용한 결과물은 나오지 않았다.
기술:
시장 경쟁업체는 웹사이트나 시장 정보를 수집하여 경쟁 정보 보고서를 작성합니다.
흩어진 메모가 아닙니다.
구조화된 결과물, 즉 포지셔닝 결정을 내릴 때 실제로 참고할 수 있는 그런 결과물입니다.
작동 원리:
경쟁사 분석은 실질적인 결과를 가져올 때만 유용합니다.
대부분의 경우 그렇지 않습니다.
연구 결과가 제대로 정리되지 않기 때문입니다.
더 급한 일이 생길 때까지 탭이나 문서, 혹은 머릿속에만 머물러 있죠.
이것이 관찰에 형식을 부여합니다.
그리고 바로 그 형식 덕분에 관찰 내용이 행동으로 이어질 수 있는 무언가로 바뀌는 것입니다.

링크: 튜토리얼 보기 | 스킬 다운로드
제가 더 나은 결정을 내리는 데 도움이 되는 클로드의 가장 중요한 능력
저는 클로드 스킬이 25개 이상 있어요.
그중에서 의사 결정에 가장 유용한 스킬이 이거예요.
비즈니스 운영에 필요한 기술
6) 워크플로 시각화 도구
기술:
워크플로 시각화 도구는 프로세스, 비즈니스 시스템 또는 운영 설정을 대화형 시각적 지도로 변환합니다.
단계, 트리거, 구성 요소, 연결된 도구 등 모든 것을 한 곳에 모아, 단순히 무엇인지 나열하는 것이 아니라 어떻게 서로 연결되는지 보여줍니다.
작동 원리:
단계 목록은 무엇이 있는지 알려줍니다.
지도는 작동 방식을 알려줍니다.
그 차이점은 시스템을 다른 사람에게 설명해야 할 때, 문제가 발생하는 부분을 찾아야 할 때, 또는 실수로 건드리지 말아야 할 부분을 건드리지 않고 개선해야 할 부분을 파악해야 할 때 중요합니다.

링크: 튜토리얼 보기 | 스킬 다운로드
7) 계약 검토자
문제:
계약서를 빨리 읽는 것은 쉽습니다.
하지만 제대로 읽는 것은
전혀 다른 문제입니다.
어려운 건 계약서의 길이가 아니라, 무엇을 살펴봐야 하는지 아는 것입니다.
문제가 생기기 전까지는 괜찮아 보이는 조항, 있어야 하지만 없는 보호 장치, 표준처럼 보이지만 그렇지 않은 조항들 말이죠.
기술:
계약서를 업로드하면 실제로 중요한 부분만 추려내어 분석해줍니다.
계약서에 서명하기 전에 주의해야 할 핵심 용어, 위험 신호, 경고 신호, 누락된 보호 장치 및 이의를 제기해야 할 사항들을 살펴보겠습니다.
작동 원리:
변호사를 대체하는 것은 아닙니다.
하지만 대부분의 사람들에게 훨씬 더 유용한 역할을 합니다.
바로 어디에 먼저 주의를 기울여야 하는지 알려주는 것이죠.
그것만으로도 문서에 접근하는 방식이 달라집니다.
모든 줄을 똑같은 걱정을 하며 읽는 대신, 어디에서 속도를 늦춰야 하고 어디에서 긴장을 풀어야 하는지 정확히 알게 됩니다.

링크: 튜토리얼 보기 | 스킬 다운로드
8) 결정위원회
문제:
어떤 결정들은 너무나 중요해서 한 가지 관점에서만 바라볼 수 없습니다.
진정한 위험은 항상 잘못된 결정을 내리는 데 있는 것은 아닙니다.
때로는 충분한 반발 없이, 불편한 질문을 던지는 사람 없이, 다양한 관점 사이의 진정한 갈등 없이 성급하게 결정을 내리는 것이 위험일 수 있습니다.
기술:
디시전 카운슬은 여러 전문가 페르소나를 동시에 활용하여 각기 다른 관점에서 의사결정을 분석합니다.
그런 다음 이러한 분석 결과를 종합하여 명확한 다음 단계를 포함한 최종 권장 사항을 제시합니다.
먼저 다양한 관점들이 구조적으로 충돌하는 모습을 보게 되고, 그 후에 해답이 나옵니다.

링크: 가이드 읽기 | 스킬 다운로드
9) 빠른 검색
문제:
연구는 금방 복잡해진다.
질문 하나로 시작하는데, 그 질문이 다른 자료로 이어지고, 또 다른 의견이 나오고, 결국엔 필요했는지조차 확신할 수 없는 세 페이지 분량의 배경 설명이 쏟아져 나오죠.
작업을 마칠 때쯤이면 열려 있는 탭은 많지만 전체적인 상황은 명확하지 않을 겁니다.
기술:
주제를 입력하면 모든 내용을 구조화된 요약 보고서로 압축해 줍니다.
저는 이 도구를 사용해서 클로드 코워크의 새로운 릴리스를 분석했습니다.
요약, 기능, 요구 사항, 장점, 단점, 가격, 그리고 최종 결과까지 모든 것을 한 곳에서 정리된 상태로 확인할 수 있었습니다.

링크: 튜토리얼 보기 | 스킬 다운로드
코딩 없이 구축하기 위한 기술
10) 프런트엔드 디자인
문제:
인공지능이 생성한 인터페이스 중 상당수는 기술적으로 제대로 작동합니다.
아무도 신경 쓰지 않은 것처럼 보이네요.
코드는 제대로 실행되지만, 결과물은 마치 5초 만에 뚝딱 만들어 놓고 다시는 손대지 않은 것처럼 느껴집니다.
평범한 레이아웃, 기본 글꼴 등, 의도적인 느낌이 전혀 들지 않습니다.
기술:
프런트엔드 디자인은 클로드 코드의 공식 스킬로, 결과물을 실제 서비스에 더 가까운 형태로 만들어줍니다.
더 나은 타이포그래피. 더 강력한 시각적 디자인. 단순히 먼저 나온 것을 받아들인 것이 아니라, 누군가 진정으로 선택을 거쳐 만들어낸 듯한 UI.

링크: 튜토리얼 보기 | 스킬 다운로드
11) 설계 구현
문제:
Figma에서 코드로 변환하는 것은 실제로 해보기 전까지는 간단해 보입니다.
바로 그때 사소한 불일치가 드러나기 시작합니다.
간격이 약간 어긋나고, 부품들이 원래 위치에서 벗어납니다.
최종 결과물은 비슷해 보이지만 , 설계에 참여했던 사람이라면 누구나 뭔가 잘못됐다는 것을 알 수 있습니다.
기술:
Implement Design은 디자인을 훨씬 더 높은 시각적 완성도로 실제 사용 가능한 코드로 변환하는 데 사용할 수 있는 Figma의 공개 스킬입니다.
이러한 능력 덕분에 클로드는 설계에서 구현으로 넘어가는 과정을 더욱 체계적으로 진행할 수 있게 되었고, 따라서 설계 내용과 실제 구현된 내용 사이의 격차를 최소화할 수 있었습니다.

링크: 튜토리얼 보기 | 스킬 다운로드
스킬 설치 방법
클로드에게 스킬을 추가하려면 아래 단계를 따르세요(.zip 또는 skill.md 파일).
사용자 정의 → 스킬 → "+" → 스킬 생성 → 스킬 업로드 → .zip 또는 skill.md 파일 업로드

만약 .zip 파일에 여러 스킬이 포함되어 있다면 (이 가이드에서 공유하는 일부 파일처럼), 해당 .zip 파일을 플러그인 폴더에 추가해야 합니다.
사용자 정의 → 개인 플러그인 → "+" → 플러그인 만들기 → 플러그인 업로드 → 파일 업로드

한 가지 더
이제 여러분은 매주 몇 시간씩 절약할 수 있는 11가지 기술을 습득했습니다.
하지만 스킬은 클로드를 제대로 사용하는 방법, 즉 프롬프트, 워크플로, 모든 것이 원활하게 작동하도록 설정하는 방법을 실제로 잘 알 때 가장 효과적입니다.
그게 바로 제 뉴스레터 구독자들이 받는 혜택입니다.
CLAUDE.md에 꼭 필요한 4줄
2026년 4월, 단 한 주 만에 Anthropic은 Claude Opus 4.7을 출시하고, Claude Design이라는 새로운 제품을 선보였으며, 노트북이 닫혀 있을 때도 실행되는 루틴 기능을 추가했습니다.
같은 날, OpenAI는 Mac에서 클릭하고 타이핑하는 병렬 에이전트를 추가하여 Codex의 성능을 한층 끌어올렸습니다.
이제는 흔한 일이 되었습니다.
2026년 4월은 LLM 출시가 가장 많았던 달 중 하나로 기록되었습니다.
기업 코드의 약 65~70%는 AI로 작성되었으며, 50% 이상의 기업이 AI 도입을 " 혼란스러운 난장판 "이라고 표현합니다.
그런데 이 분야에서 가장 많은 별점을 받은 개발자 리소스는 프레임워크, 플러그인 또는 모델이 아닙니다.
마크다운 파일에 있는 네 문장입니다.
GitHub 저장소 하나. 별점 6만 개 .
종속성도 없고, API도 없고, 빌드 단계도 필요 없습니다.
안드레이 카르파티가 1월에 게시한 내용에서 도출된 네 가지 행동 지침이 담긴 파일 하나 CLAUDE.md. 6만 명의 개발자가 북마크한 이 파일은 이번 주 어떤 제품 발표보다도 AI 기반 코딩의 진짜 병목 현상에 대해 더 많은 것을 알려줍니다.
지난 주말에 최신 Claude Code 업데이트에 맞춰 제 에이전트를 마이그레이션 CLAUDE.md하는 작업을 했습니다.
몇 달에 걸쳐 공들여 만든 47개의 규칙이었는데, 에이전트가 절반을 무시하고 제가 작성하지도 않은 규칙을 마구잡이로 만들어내는 겁니다.
그때 이 저장소를 발견했고, 문제가 규칙 자체가 아니라 규칙의 개수라는 걸 깨달았습니다.

카르파티가 실제로 진단한 내용은 무엇이었을까요?
2026년 1월, 안드레이 카르파티는 대부분의 AI 관련 논평과는 다른 분위기의 글을 올렸습니다 . 그는 무언가를 발표하려는 것이 아니라, 어떤 문제가 발생했는지 설명하고 있었습니다.
2025년 11월부터 12월까지 약 6주 동안, 그는 수동 코딩 80%, 상담원 지원 20%에서 완전히 정반대인 80% 상담원 지원, 20% 수정으로 전환했습니다.
그는 이를 " 약 20년간의 프로그래밍 경력에서 가장 큰 변화 "라고 불렀습니다.
하지만 그 글은 축하하는 내용이 아니었습니다.
오히려 진단을 위한 것이었습니다.
모델들이 코드 자체에서 실패한 것이 아니었습니다.
판단력 부족이 문제였습니다.
"모델들은 사용자를 대신해 잘못된 가정을 세우고 검증도 없이 그대로 진행합니다.
" 카르파티는 더 근본적인 문제를 정확히 짚어냈습니다.
"모델들은 혼란을 제대로 관리하지 못하고, 명확한 설명을 요구하지도 않으며, 불일치를 드러내지도
않고, 장단점을 제시하지도 않으며, 마땅히 반박해야 할 때에도 이의를 제기하지 않습니다."
"사용자 데이터 내보내기"를 요청하면 에이전트는 JSON 형식을 가정하고 디스크에 모든 필드를 포함하여 페이지네이션을 건너뛰고 저장합니다.
"어떤 형식을 원하시는지 확실하지 않습니다"라고 말하는 단계 없이 바로 형식을 선택해서 실행합니다.
라인 1은 바로 여기서 나옵니다.
"그들은 코드를 지나치게 복잡하게 만들고 API를 과도하게 추상화하는 것을 정말 좋아합니다.
" 카르파티의 표현을 빌리자면, "100줄이면 충분한데 1,000줄이 넘는 코드로 비대해진 구조를 구현한다"는 것입니다.
할인 계산기를 요청했는데 추상 기본 클래스, 열거형, 데이터 클래스 설정, 그리고 40줄의 설정 코드가 포함된 전략 패턴이 나왔습니다.
에이전트는 오늘의 문제가 아니라 내일의 요구 사항을 위해 구축됩니다.
이것은 2번 라인에 직접 연결됩니다.
"그들은 여전히 때때로 자신들이 충분히 이해하지 못하는 부작용을 이유로 주석이나 코드를 수정하거나 삭제하는데, 이는 설령 그것이 작업과 직접적인 관련이 없더라도 마찬가지입니다."
에이전트에게 버그 수정을 요청했는데, PR(풀 리퀘스트)에서 따옴표 형식을 작은따옴표에서 큰따옴표로 바꾸고, 요청하지도 않은 타입 힌트를 추가하고, 인접한 코드까지 다시 작성해 버렸습니다.
수정된 코드는 단 3줄이었는데, 변경된 코드는 무려 40줄이나 됩니다.
3번째 줄이 존재하는 이유는 바로 이것입니다.

그 글이 공감을 얻은 이유는 해결책을 제시하지 않았기 때문입니다.
카르파티는 해결책을 내놓지 않았습니다.
그는 실패 원인을 명확하게 설명했고, 며칠 만에 누군가가 그 내용을 네 줄짜리 CLAUDE.md파일로 변환하여 깃허브에 게시했습니다.
하지만 네 번째 문장은 단순히 규율을 넘어 카르파티 자신이 암시했던 내용을 담고 있습니다.
" LLM은 특정 목표를 달성할 때까지 반복적인 과정을 거치는 데 매우 능숙합니다.
무엇을 해야 할지 지시하지 마세요.
성공 기준을 제시하고 스스로 작동하는 모습을 지켜보세요."
그게 바로 4번째 줄입니다.
그리고 바로 그 줄 덕분에 이 모든 것이 단순한 스타일 가이드 이상의 의미를 갖게 되는 거죠.
DESIGN.md에 꼭 필요한 9가지 섹션
7만 명의 개발자가 북마크한 것, 구글이 오픈소스로 공개한 것, 그리고 일반 마크다운이 디자인 툴체인보다 나은 이유
레벨업.gitconnected.com
4줄
행동 관련 내용 전체입니다.CLAUDE.md
1. 추측하지 마세요.
혼란스러운 점을 숨기지 마세요.
장단점을 명확히 드러내세요.2. 문제를 해결하는 최소한의 코드만 작성하십시오. 추측성 코드는 일절 포함하지 마십시오.
3. 꼭 필요한 것만 만지세요.
자신이 어지럽힌 것만 치우세요.4. 성공 기준을 정의합니다.
기준이 충족될 때까지 반복합니다.
이게 전부입니다.
각 줄은 카르파티의 고장 모드 중 하나에 직접적으로 연결됩니다.

각 방법이 효과적인 이유를 자세히 살펴보겠습니다.
아래의 전후 예시는 저장소의 EXAMPLES.md 파일 에서 가져온 것으로 , 각 원칙에 대한 자세한 설명이 포함되어 있습니다.
코딩하기 전에 생각하세요: 추측하지 마세요.
혼란스러운 점을 숨기지 마세요.
장단점을 명확히 드러내세요.
이 솔루션은 AI 코딩 에이전트의 가장 흔한 문제점, 즉 언제 질문해야 할지 추측하는 문제를 해결합니다.
이 줄이 없으면 상담원에게 "사용자 데이터 내보내기 기능을 추가해 주세요"라고 말했을 때 다음과 같은 일이 발생합니다.
def export_users ( format = 'json' ):
users = User.query.all ( )
if format == 'json' :
with open ( 'users.json' , 'w' ) as f:
json.dump([u.to_dict() for u in users], f)
return f"Exported { len (users)} users"
에이전트는 JSON 형식을 가정했습니다.
모든 사용자를 가정했습니다.
파일 출력을 디스크에 저장하는 것을 가정했습니다.
어떤 필드를 포함할지 가정했습니다.
이러한 결정 사항에 대해 전혀 언급하지 않았습니다.
그냥 알아서 처리했습니다.
이 원칙에 따르면 에이전트의 첫 번째 반응은 다음과 같습니다.
구현하기 전에 다음 사항을 명확히 해야 합니다 . 1.
범위 : 모든 사용자를 내보낼 것인가 , 아니면 필터링 된 일부 사용자만 내보낼 것인가 ?
2. 형식: JSON 다운로드, CSV 파일 또는 API 엔드포인트 중 어떤 것을 사용할 것인가?
3. 필드: 어떤 사용자 필드를 내보낼 것인가? 일부 필드는 민감한 정보일 수 있습니다.
4. 규모: 사용자 수가 얼마나 되는가? (접근 방식에 영향을 미칩니다)
네 가지 가정이 아니라 네 가지 질문입니다.
코드는 답변 후에 나오는 것이지, 답변 전에 나오는 것이 아닙니다.
이것이 생각보다 중요한 이유: LLM(언어 모델)은 불확실성을 자연스럽게 외부화하지 않습니다.
LLM은 완료를 기반으로 학습되었지, 멈춤을 기반으로 학습되지 않았습니다.
학습 데이터의 모든 토큰은 계속 진행됩니다.
"확실하지 않다"라고
말하기 위해 멈추는 것은 이러한 모델이 텍스트를 생성하는 방식을 학습한 기본 원리에 어긋납니다.
이 코드는 모델이 수행할 수 있지만 기본값으로 사용하지 않는 동작을 강제합니다.
기능을 추가하는 것이 아니라 기본값을 재정의하는 것입니다.
단순함이 최우선: 문제를 해결하는 데 필요한 최소한의 코드만 작성합니다.
불필요한 추측은 금물입니다.
이는 성급한 추상화를 방지합니다.
이 기능이 없으면 "할인율을 계산하는 함수"를 요청했을 때 다음과 같은 결과가 나옵니다.
class DiscountStrategy ( ABC ):
@abstractmethod
def calculate ( self , amount: float ) -> float:
pass
class PercentageDiscount (DiscountStrategy):
def __init__ ( self , percentage: float ):
self.percentage = percentage
def calculate ( self , amount: float ) -> float:
return amount * ( self.percentage / 100 )
class FixedDiscount (DiscountStrategy):
# ... 20줄 더
class DiscountCalculator
:
def __init__ ( self , config: DiscountConfig ):
# ... 15줄 더 설정
추상 기본 클래스. 전략 패턴. 설정 데이터 클래스. 연산 코드만 40줄이 넘습니다.
다음 원칙을 바탕으로:
def calculate_discount ( amount : float , percent : float ) -> float :
return amount * (percent / 100 )
함수 하나, 로직 한 줄. 나중에 전략 패턴이 필요하면 그때 리팩토링하세요.
지금은 아닙니다.
섣부른 판단으로 리팩토링하지 마세요.
대부분의 기사에서 간과하는 핵심은 바로 이것입니다.
지나치게 복잡한 버전이 명백히 틀린 것은 아닙니다.
오히려 실제 디자인 패턴을 따르고 있을 가능성이 높습니다.
숙련된 엔지니어라면 대규모 청구 시스템에서 전략 패턴을 실제로 사용할
수도 있습니다.
문제는 타이밍 입니다 . 성급한 추상화는 누적되는 비용을 수반합니다.
코드가 많아질수록 버그 발생 가능성이 높아지고, 코드 리뷰어의 인지 부담이 커지며, 방향 전환이 필요할 때 관성이 커집니다.
에이전트는 아직 존재하지도 않고 어쩌면 영원히 존재하지 않을 요구사항을 기반으로 구축됩니다.
좋은 코드는 미래의 문제를 성급하게 해결하는 것이 아니라, 오늘날의 문제를 간단하게 해결합니다.
원본 파일에 있는 수석 엔지니어 테스트가 핵심을 정확히 짚고 있습니다.
"수석 엔지니어가 이것이 지나치게 복잡하다고 말할까요?" 만약 그렇다면, 단순화하세요.

수술 후 변화: 꼭 필요한 부분만 만지세요.
자신이 저지른 실수만 수습하세요.
이 기능은 차이점을 보호합니다.
예를 들어, 빈 이메일로 인해 유효성 검사기가 오류를 일으키는 버그를 수정해 달라고 상담원에게 요청한다고 가정해 보겠습니다.
이 원칙이 없다면 차이점은 다음과 같이 표시될 것입니다.
- user_data.get ('email') 이 없으면 ,
email을 user_data.get ( 'email' ,
'' ).strip () 으로 제거 하고 , email이 없으면 ValueError ( "이메일이 필수입니다.
" ) 를 발생시킵니다 . - user_data[ 'email' ] 에 '@'가 없거나 email.split ( ' @' )[ 1 ] 에 '. ' 이 없으면 ValueError("유효하지 않은 이메일입니다.
")를 발생시킵니다.
- user_data.get('username')이 없으면, username을 user_data.get('username', '').strip()으로
제거하고, username이 아니면 ValueError ( " 사용자 이름 이 필수 입니다 . " ) 를 발생 시킵니다 . username 의 길이 가 3 보다 작 으면 ValueError ( " 사용자 이름 이 너무 짧 습니다 . " ) 를 발생시킵니다 . username.isalnum () 이 아니면 ValueError ( "사용자 이름은 영숫자여야 합니다.
" ) 를 발생시킵니다.
버그 수정 사항은 빈 이메일 처리 문제였습니다.
에이전트는 또한 이메일 유효성 검사를 "개선"하고, 사용자 이름 길이 검사를 추가하고, 영숫자 사용을 강제하고, 변수 이름을 변경했습니다.
이러한 변경 사항은 전혀 요청된 것이 아니었습니다.
이 원칙에 따르면, 차이는 극명합니다.
- user_data.get ('email') 이 없으면
email을 user_data.get ( 'email' ,
'' ) 로 설정 합니다.
email이 없거나 email.strip () 이 아니면 ValueError ( "이메일이 필요합니다" ) 를 발생시킵니다 . - user_data[ 'email' ] 에 ' @ ' 가 없으면 valueError ( "유효하지 않은 이메일입니다" ) 를 발생시킵니다 .
변경된 모든 줄은 버그 보고서로 연결됩니다.
그 외에는 아무것도 없습니다.
진정한 핵심은 코드의 깔끔함이 아니라 감사 가능성입니다.
에이전트의 변경 내역에 40줄의 변경 사항이 있는데 요청으로 연결되는 추적 정보가 3개밖에 없다면, 나머지 37줄을 하나하나 검토하지 않고는 신뢰할 수 없습니다.
이는 사소한 불편함이
아니라 AI가 생성한 모든 코드에 부과되는 검토 비용입니다.
정밀한 수정을 통해 AI 출력물을 필요한 속도로 검토할 수 있습니다 . 변경 내역이 작을수록 더 빠르게 신뢰하고 병합하여 다음 단계로 넘어갈 수 있습니다.
원본 파일에는 미묘하지만 중요한 뉘앙스가 있습니다.
즉, 변경 사항으로 인해 사용되지 않는 임포트나 더 이상 사용되지 않는 변수와 같은 불필요한 코드가 발생하면 이를 정리해야 합니다.
하지만 요청받지 않는 한 기존의 사용되지 않는 코드는 건드리지 마십시오. 당신이 만든 코드는 당신이 정리해야 하고, 그들이 만든 코드는 그들이 처리해야 합니다.
목표 중심 실행: 성공 기준을 정의합니다.
검증될 때까지 반복합니다.
앞의 세 가지 원칙은 일종의 안전장치입니다.
행동을 제한하는 역할을 하죠. 하지만 이 원칙은 다릅니다.
잠재력을 발휘할 수 있도록 해주는 열쇠입니다.
이것이 바로 카르파티의 관찰을 활용하는 원리입니다.
그는 LLM이 "특정 목표를 달성할 때까지 반복하는 데 매우 능숙하다"는 점을 발견했습니다.
문제는 에이전트가 반복할 수 없다는 것이 아니라, 검증 가능한 목표 대신 모호한 지침을 제공한다는 것입니다.
이 원칙이 없으면 "인증 시스템을 수정하세요"라고 말하면 상담원은 다음과 같이 응답합니다.
인증 시스템을 다음과 같은 방법으로 개선하겠습니다.
1. 코드 검토
2. 문제점 파악
3. 개선 사항 적용
4. 변경 사항 테스트
계획이 모호하고, 성공 기준도 없고, 검증 방법도 없다.
그냥 뭔가 바꾸고 나면 끝이라고 할 것 같다.
이 원칙에 따라 동일한 요청이 다음과 같이 변환됩니다.
1. 테스트 작성: 비밀번호 변경 → 기존 세션 무효화
→ 검증: 테스트 실패 ( 버그 재현 ) 2.
구현: 비밀번호 변경 시 세션 무효화 → 검증: 테스트 통과 3. 예외 상황: 다중 세션, 동시 변경 → 검증: 추가 테스트 통과 4. 회귀 테스트: 기존 인증 테스트는 여전히 통과 → 검증: 전체 테스트 스위트 통과
각 단계마다 확인 절차가 있습니다.
에이전트는 "완료"의 기준을 알고 있으므로 독립적으로 반복 작업을 수행할 수 있습니다.
명확한 성공 기준이 지속적인 지원을 대체합니다.

이 원칙을 다른 세 가지 원칙과 구분 짓는 것은 바로 ' 코딩 전 사고', '단순 우선', '정밀한 수정'입니다.
이는 규율입니다.
잘못된 행동을 예방하는 역할을 합니다.
반면 '목표 중심 실행'은 레버리지입니다.
에이전트가 이미 잘하지만
적절한 프롬프트 구조 없이는 활성화되지 않는 행동을 이끌어내는 역할을 합니다.
앞의 세 가지 원칙은 에이전트를 덜 성가시게 만드는 반면, 네 번째 원칙은 에이전트의 능력을 향상시킵니다.
그리고 이 차이가 중요합니다.
규율은 효율이 떨어지지만, 레버리지는 복리 효과를 냅니다.
한 가지 주의할 점은, 이 예시들은 깔끔한 단일 파일 작업만을 보여준다는 것입니다.
여러 팀과 복잡하게 얽힌 의존성을 가진 10만 줄 규모의 모노레포에서 이 4줄짜리 코드가 얼마나 효과적인지 직접 확인하고 싶습니다.
단일 개발자 프로젝트는 쉬운 경우입니다.
더 어려운 문제는 행동 지침만으로 대부분의 엔터프라이즈 코드베이스가 실제로 가지고 있는 복잡성에 대응할 수 있는지 여부입니다.
구성의 역설
AI 에이전트가 오작동할 때 자연스러운 본능은 규칙을 더 추가하는 것입니다.
세미콜론을 사용하지 마세요.
항상 오류 처리를 추가하세요.
저장소의 명명 규칙을 따르세요.
함수형 패턴을 선호하세요.
TypeScript 엄격 모드를 사용하세요.
이러한 본능은 엄청난 규모의 생태계를 만들어냈습니다.
한 인기 있는 GitHub 툴킷은 135개의 에이전트, 35개의 엄선된 스킬, 마켓플레이스를 통해 제공되는 40만 개 이상의 스킬, 176개의 플러그인, 그리고 42개의 명령어를 포함하고 있습니다.
또 다른 툴킷은 30개의 특화된 에이전트와 136개의 스킬을CLAUDE.md 제공합니다.
현재 최소 5가지의 경쟁적인 설정 형식(예: , AGENTS.md, .cursorrules, copilot-instructions.md, ) 이 존재합니다 . 심지어 규칙을 형식 간에 변환하는 도구.windsurfrules 도 있습니다 .
이 생태계는 대부분의 팀이 보유한 엔지니어 수보다 더 많은 구성 옵션을 제공합니다.

문제는 예상대로 확장되지 않는다는 것입니다.
Claude Code는 개별 규칙 파일의 길이를 6,000자, 전체 규칙 파일의 길이를 12,000자로 제한합니다.
이러한 제한이 있는 데에는 이유가 있습니다.
특정 임계값을 넘어서 규칙을 추가하면 에이전트가 제대로 작동하지 않고 혼란스러워지기 때문입니다.
Anthropic의 공식 문서에도 이 내용이 명확하게 나와 있습니다.
"각 줄마다 '이 부분을 삭제하면 Claude가 오류를 범할까?'라고 자문해 보세요.
오류가 발생하지 않는다면 삭제하세요."
신입 사원 온보딩을 생각해 보세요.
모든 가능한 시나리오를 다룬 50페이지짜리 직원 핸드북을 줄 수도 있습니다.
아니면 회사가 실제로 지키는 네 가지 원칙만 알려주고 직원들이 판단력을 발휘하도록 맡길 수도 있습니다.
핸드북은 서랍 속에 처박히겠지만, 그 원칙들은 실제로 활용될 것입니다.

이것이 바로 구성의 역설입니다.
규칙이 많을수록 더 많은 제어력을 가진 것처럼 느껴지지만, 행동적 기반을 넘어서면 신호와 경쟁하는 노이즈를 추가합니다.
55,000개의 별점은 미니멀리즘을 미학적으로 옹호하는 것이 아닙니다.
행동적 제약이 기능 목록보다 더 효과적이라는 통찰력에 대한 지지입니다.
이 네 줄의 규칙이 효과적인 이유는 에이전트가 무엇을 하는지가 아니라 어떻게 생각하는지를 결정하기 때문입니다.
이 규칙들은 프로젝트, 언어, 문제 유형을 가리지 않고 적용 가능합니다.
예를 들어 "TypeScript 엄격 모드 사용"과 같은 규칙은 특정 기술 스택에 적용되지만, "추측하지 마라"는 규칙은 모든 것에 적용됩니다.
파일에 실제로 무엇을 넣어야 할까요?
가장 빠른 방법은 이 문제를 제기한 저장소에서 파일을 직접 설치하는 것입니다.
옵션 A: Claude Code 플러그인 (권장)
Claude Code 내에서 마켓플레이스를 추가하고 설치하세요.
/플러그인 마켓플레이스 추가 forrestchang/andrej-karpathy-skills
/플러그인 설치 andrej-karpathy-skills@karpathy-skills
이렇게 하면 모든 프로젝트에서 가이드라인을 자동으로 사용할 수 있습니다.
옵션 B: 파일을 직접 다운로드
새로운 프로젝트:
curl -o CLAUDE .md https: //raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md
기존 프로젝트 (현재 파일에 추가):
echo "" >> CLAUDE.md
curl https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md >> CLAUDE.md
전체 파일은 4가지 원칙 각각에 대해 하위 항목과 예시를 통해 자세히 설명합니다.
하지만 핵심은 여전히 그 네 가지 핵심 원칙입니다.
나머지는 모두 부연 설명일 뿐입니다.
행동적 기반이 마련되면 그 위에 프로젝트별 컨텍스트를 얇게 덧입히세요.
코딩 방법에 대한 규칙이 아니라, 에이전트가 파일을 읽어서 추론할 수 없는 컨텍스트를 말입니다.
빌드 명령. 에이전트는 프로젝트를 실행하는 방법을 알아야 합니다.
## 프로젝트
- 빌드: `npm run build`
- 테스트: `npm test`
- 린트: `npm run lint -- --fix`
코드에는 나타나지 않는 규칙들. 기존 코드에서는 보이지 않는 결정 사항들:
## 규칙
- API 오류는 { error: string , code: number }를 반환하며 , 예외를 발생 시키지 않습니다.
- 모든 날짜는 UTC 로 저장되며, 사용자 의 시간대 에 맞춰 표시됩니다.
- 기능 플래그는 config/flags.ts 파일에 저장되며, 코드 내에 직접 입력하지 않습니다.
과거의 실패에서 얻은 교훈. 이전에 고장 났던 것들에 대한 한 줄짜리 핵심 사항:
## 주의
- 결제 서비스 타임아웃은 기본값 인 5초가 아닌 30초 입니다 . - /internal에서 임포트하지 마세요.
공개 API 빌드가 실패합니다.

그게 전부입니다.
저장소의 동작 기반, 빌드 명령, 몇 가지 규칙, 그리고 경고 메시지가 있으면 됩니다.
4번째 줄 이후에 추가하는 모든 줄에 대한 판단 기준은 "이 부분을 제거하면 에이전트가 복구할 수 없는 오류를 발생시킬까?"입니다.
답이 "아니오"라면 해당 줄은 그대로 두세요.
파일에 넣지 말아야 할 내용: 에이전트가 코드에서 읽을 수 있는 아키텍처 개요, 기존 패턴에서 추론할 수 있는 스타일 가이드, 저장소에서 찾을 수 있는 종속성 목록 package.json또는 저장소를 통해 접근할 수 있는 문서.
이미 있는 내용을 중복해서 작성하지 마세요.
네 줄로는 부족한 경우
이 지침은 행동적인 측면을 잘 다루고 있습니다.
하지만 행동이 유일한 측면은 아닙니다.
복잡한 다중 파일 리팩토링. 전체 모듈의 구조를 변경하고, 함수를 파일 간에 이동하고, 임포트 체인을 업데이트할 때, 에이전트는 동작 제약 조건으로는 제공할 수 없는 아키텍처 컨텍스트가 필요합니다.
에이전트가 어떤 파일이 어떤 파일에 의존하는지
알지 못하면 "추측하지 마세요"라는 원칙은 도움이 되지 않습니다.
대규모 리팩토링의 경우, 아키텍처 섹션을 간략하게 추가 CLAUDE.md하거나 작업을 에이전트가 한 번에 하나씩 처리할 수 있는 더 작고 범위가 명확한 작업으로 분할해야 합니다.
규제 산업. 의료, 핀테크 또는 기타 규정 준수 요건이 있는 분야에서 일하는 경우, 4가지 행동 지침만으로는 "개인 식별 정보(PII)를 절대 기록하지 마십시오" 또는 "모든 API 변경 사항에 대한 보안 검토를 의무화하십시오"와 같은 내용을
모두 다룰 수 없습니다.
분야별 특수한 가이드라인은 행동 지침과는 별개의 문제입니다.
4가지 지침을 대체하는 것이 아니라, 함께 추가해야 합니다.
팀 규모의 일관성 유지. 개발자 한 명의 경우는 CLAUDE.md간단합니다.
하지만 20명의 엔지니어가 각자의 에이전트에 대한 행동 규범을 공유하도록 하는 것은 설정 문제가 아니라 조정 문제입니다.
바로 이 지점에서 AGENTS.md(리포지토리에 커밋되고 도구에 구애받지 않는) 형식과 같은 것들이 중요해집니다.
네 줄짜리 코드는 팀의 출발점일 뿐이며, 팀은 프로젝트별 규칙 중 어떤 것을 우선시할지에 대한 합의도 필요합니다.
도구 호환성. 이 지침은 특히 Claude Code를 위해 작성되었습니다.
Cursor, Copilot 및 Codex는 일부 중복되지만 서로 다른 오류 모드를 가지고 있습니다.
하지만 원칙은 동일하게 적용됩니다.
"추측하지 마십시오"는 어떤 에이전트를
사용하든 좋은 조언입니다.
그러나 구체적인 표현 방식과 에이전트의 반응 정도는 도구에 따라 다릅니다.
Cursor를 사용하는 경우, 이 지침을 .cursorrules형식에 맞게 수정하고 에이전트가 동일하게 해석하는지 테스트해야 합니다.

솔직히 말씀드리자면, 6만 개의 별점은 공감대를 형성하는 신호일 뿐, 효과를 입증하는 증거는 아닙니다.
이 가이드라인이 출력 품질을 얼마나 향상시키는지 정확하게 보여주는 엄격한 전후 비교 기준은 없습니다.
어떤 사이트에서는 카르파티 가이드라인을 사용했을 때 정확도가 94% 라고 주장 하지만, 그 수치를 확정적인 것으로 받아들이기 전에 해당 방법론을 살펴봐야 할 것입니다.
우리가 가진 것은 많은 개발자들의 경험적 공감대입니다.
이는 의미 있는 결과이지만, 통제된 연구 결과는 아닙니다.
행동적 병목 현상
텍스트 파일에 6만 개의 별표가 표시되어 있다는 사실은 제품 발표에서는 알 수 없는 중요한 점을 시사합니다.
바로 AI 기반 코딩의 병목 현상은 기능이 아니라 행동 방식이었다는 것입니다.

모델은 코드를 작성할 수 있습니다.
이미 꽤 오래전부터 코드를 작성할 수 있었죠. 하지만 언제 작성을 멈춰야 할지, 시작하기 전에 무엇을 물어봐야 할지, 얼마나 수정해야 할지, 그리고 완료 여부를 어떻게 검증해야 할지 정확하게 판단하는 것은 어렵습니다.
이는 지능적인 문제가 아니라 행동적인 문제입니다.
그리고 행동적인 문제는 모델을 더 똑똑하게 만든다고 해결되는 것이 아니라, 모델에게 어떻게
행동해야 하는지 알려줌으로써 해결됩니다.
그래서 단 네 문장이 플러그인, 에이전트, 스킬로 구성된 생태계보다 뛰어난 성능을 보인 것입니다.
생태계 자체가 잘못됐다는 뜻은 아닙니다.
오히려 생태계는 기능적인 측면만 해결하고 있을 뿐, 행동적인 측면은 여전히 제약 조건으로 남아 있습니다.
모든 모델 개선은 도움이 됩니다.
하지만 상담원들이 불확실성을 안정적으로 관리하고, 변경 범위를 설정하고, 작업을 검증할 수 있을 때까지는, 4줄짜리 명령어가 어떤 기능 발표보다 캐릭터당 더 많은 역할을 계속해서 수행할 것입니다.
내일 제 워크플로에서 실제로 바꾸고 싶은 부분은 다음과 같습니다.
먼저, 제 코드를 열고 CLAUDE.md에이전트가 코드베이스를 읽어서 알아낼 수 있는 모든 규칙을 제거합니다.
그리고 만약 없다면 4개의 행동 관련 규칙을 추가하고, 앞으로 추가하고 싶은 모든 규칙에 대해 다음 질문을 스스로에게 던져봅니다.
"이 규칙이 에이전트의 사고방식을 바꾸는가, 아니면
단순히 에이전트의 행동만을 바꾸는가?" 후자라면, 아마도 해당 규칙은 파일에 포함될 필요가 없을 것입니다.
더 자세히 알아보려면 저장소의 EXAMPLES.md 파일에 각 원칙에 대한 전체 전후 코드 예시가 나와 있으며, 4번째 줄에 대한 다단계 검증 패턴도 포함되어 있습니다.
모델은 계속해서 더 똑똑해질 것이고, 도구는 더욱 강력해질 것입니다.
하지만 모델이 스스로 판단하는 능력을 갖추기 전까지는 행동적인 측면에서 병목 현상이 계속될 것입니다.
그리고 그때까지는 마크다운 파일에 적힌 네 문장이 제품 출시 주기보다 훨씬 더 나은 성과를 낼 것입니다.
클로드 코워킹 스페이스를 제대로 구축하는 데 일주일이 걸렸습니다.
여러분이 꼭 알아야 할 모든 것을 알려드릴게요.

여러분이 꼭 알아야 할 모든 것을 알려드릴게요.
AI 도구에 대해 아무도 공개적으로 말하지 않는 한 가지를 말씀드리자면, 대부분의 사람들이 AI 도구를 잘못 설정하고 있다는 것입니다.
" 뭔가를 망가뜨릴 거야 "라는 의미에서 잘못된
게 아닙니다.
" 잠재력의 80%를 낭비하는 거야 "라는 의미에서 잘못된 겁니다.
저는 클로드 코워크를 꽤 오랫동안 사용해 왔는데, 마법처럼 느껴지는 세션과 약간 더 똑똑한 구글 검색처럼 느껴지는 세션의 가장 큰 차이점은 바로 설정 방식에 있습니다.
구체적으로 말하자면, 폴더 시스템과 그 안에 있는 세 개의 파일이죠.
이 가이드는 접근 권한 얻는 방법, 폴더 구조 구축 방법, 각 파일에 넣을 내용, 그리고 실제로 도구를 효과적으로 사용하는 방법 등 모든 것을 다룹니다.
클로드 코워킹이란, 과연 무엇일까요?
대부분의 사람들은 이를 " AI 협업 도구 "라고
설명합니다.
기술적으로는 정확한 표현이지만, 설명으로서는 거의 쓸모가 없습니다.
Cowork는 사용자의 컴퓨터에 있는 파일을 읽을 수 있는 Claude의 변형 버전입니다.
폴더를 지정하면 그 안에 있는 내용을 읽어오고, 모든 대화는 이미 로드된 컨텍스트를 기반으로 시작됩니다.
사용자의 선호도, 목표, 글쓰기 스타일, 회사 우선순위 등 모든 정보가 첫
메시지를 입력하기도 전에 Claude의 작업 메모리에 저장됩니다.
이러한 차이가 가져오는 영향은 아무리 강조해도 지나치지 않습니다.
매 회마다 자신이 누구이고 무엇을 하고 있는지 다시 설명하는 대신, 그냥… 바로 작업에 들어가면 됩니다.
Anthropic은 개발자가 아닌 사람들을 위해 특별히 이 앱을 만들었습니다.
코딩도, 터미널도, API 키도 필요 없습니다.
앱을 다운로드하고 폴더를 선택하면 바로 사용할 수 있습니다.
접근 권한 얻기
- 앱을 다운로드하세요 . claude.com/download로 이동하여 컴퓨터용 데스크톱 앱을 다운로드하세요.
클로드 코워크는 웹 브라우저 버전과 다르며, 데스크톱 앱에서만 작동합니다. - 프로 계정이 필요합니다.
월 20달러 이상인 Claude Pro는 Cowork를 이용하기 위한 최소 요구 사항입니다.
이미 프로 계정을 사용 중이시라면 문제없습니다.
그렇지 않다면 지금 바로 구독하세요. - 앱에서 Cowork를 찾는 방법: 데스크톱 앱을 실행하면 채팅과 코딩 탭을 전환할 수 있는 탭이 있습니다.
Cowork는 코딩 섹션에 있으니, 이름에 속지 마세요.
코딩을 하는 것은 아닙니다.
코워킹 세션을 시작할 때는 항상 Opus 4.6 모델을 선택하세요.
가장 뛰어난 성능을 자랑하는 옵션이며, 복잡하고 섬세한 작업에 결정적인 차이를 만들어냅니다.
다른 모델도 사용 가능하지만, 중요한 작업에는 타협하지 마세요.
폴더 설정
대부분의 튜토리얼이 사람들을 혼란스럽게 하는 부분이 바로 여기입니다.
"폴더가 필요합니다"라고 언급하고는 바로 넘어가 버리죠. 하지만 폴더는 사소한 디테일이 아니라, 전체 시스템의 핵심입니다.
컴퓨터에 'Claude Cowork'라는 폴더를 만드세요.
바탕 화면, 문서 폴더 등 자주 사용하는 위치에 만드는 것이 좋습니다.
해당 폴더 안에 하위 폴더 세 개를 만드세요.
- 나에 대하여
- 출력
- 템플릿
이것이 핵심 구조입니다.
나머지 모든 것은 이 세 가지 위에 구축됩니다.
자기소개 폴더
이 폴더는 전체 시스템에서 가장 중요한 폴더입니다.
Cowork는 세션을 시작할 때마다 이 폴더를 자동으로 읽습니다.
이 폴더의 내용은 Claude가 사용자를 이해하고, 사용자에게 말을 걸고, 사용자가 부여하는 모든 작업을 처리하는 방식에 영향을 미칩니다.
'내 소개' 섹션 안에는 세 개의 파일이 필요합니다.
나에 대하여.md
이 파일은 당신의 직책이 아니라 당신이 어떤 사람인지에 대한 것입니다.
클로드가 당신과 효과적으로 협업하기 위해 필요한 실제적인 맥락, 즉 당신의 사고방식, 관심사, 원하는 결과물, 그리고 소통 방식 등을 담고 있습니다.
2,000단어(정확히는 토큰 수지만, 대략적인 단어 수입니다) 이내로 작성해 주세요.
클로드가 매 회의마다 전체 내용을 읽기 때문에, 파일이 너무 길면 작업 속도가 느려지고 가장 중요한 정보가 희석됩니다.
처음부터 시작하는 경우, 이 파일을 만드는 가장 깔끔한 방법은 클로드에게 인터뷰를 요청하는 것입니다.
Opus 4.6과 확장된 사고 기능을 활성화한 상태로 새 코워크 세션을 시작한 다음, 다음과 같이 말하세요.
" 저에 대한 소개 자료(about-me.md)를 만들기 위해 저를 인터뷰해 주셨으면 합니다.
제가 어떤 사람인지, 어떻게 생각하는지, 무엇을 중요하게 생각하는지, 그리고 어떤 방식으로 일하는 것을 선호하는지에 대해 15~20개의 구체적인 질문을 해 주세요."
클로드가 질문을 하나씩 할 것이고, 답변이 끝나면 클로드가 답변을 요약한 산문 파일로 만들어 'ABOUT ME' 폴더에 바로 저장할 수 있게 해줍니다.
이미 이전 세션에서 작성한 about-me.md 파일이 너무 길어졌다면, 수동으로 편집하는 대신 동일한 인터뷰 방식을 사용하여 내용을 줄이세요.
안티-AI 글쓰기 스타일.md
이 파일은 단 하나의 기능만 수행합니다.
클로드가 인공지능처럼 글을 쓰는 것이 아니라, 당신처럼 글을 쓰도록 만들어 줍니다.
대부분의 AI 생성 콘텐츠에는 어떤 특징을 찾아야 하는지 알면 즉시 알아볼 수 있는 패턴이 있습니다.
군더더기 문구, 과도한 구조, 불필요한 항목에 대한 글머리 기호 사용, " 참고할 만한 점은… "과 같은 표현 등이 대표적입니다.
혹시라도 무언가를 읽고 " 로봇이 쓴 것 같다 "라고 느낀 적이 있다면, 바로 이러한 패턴들을 감지하고 있는 것입니다.
anti-ai-writing-style.md 파일은 Claude에게 당신의 글에서 피해야 할 특정 패턴을 알려줍니다.
여기에는 당신이 싫어하는 단어, 부자연스럽게 느껴지는 문장 구조, 서식 규칙(과도한 굵은 글씨 금지, 한 페이지 문서에 5단계 제목 사용 금지 등), 그리고 당신이 글을 쓸 때 실제로 어떤 어조로 말하는지 등이 포함될 수 있습니다.
개인 맞춤형 스타일 가이드라고 생각하시면 됩니다.
목표는 Claude가 기본 AI 스타일이 아닌 사용자 스타일로 글을 쓰도록 하는 것입니다.
마이컴퍼니.md
about-me.md가 개인적인 정보를 담고 있다면 , my-company.md 는 전략적인 정보를 담고 있습니다.
여기에는 현재 목표, 우선순위, 앞으로 나아가고자 하는 방향,
그리고 내리려고 하는 결정 사항들이 포함됩니다.
about-me.md가 클로드에게 당신의 사고방식을 알려주고, my-company.md가 당신이 무엇을 생각하고 있는지를 알려주는 것처럼, 두 사이트의 내용이 중복되어서는 안 됩니다.
핵심을 짚어주는 날카로운 질문 6~8개에 집중하여 답변하십시오. 당신의 목표는 무엇입니까? 당신의 나침반은 무엇입니까? 당신이 적극적으로 피하려고 하는 것은 무엇입니까?
이 파일은 목표가 변화함에 따라 주기적으로 업데이트해야 합니다.
6개월 전에 작성된 my-company.md 파일은 우선순위가 바뀌었다면 오히려 오해를 불러일으킬 수 있습니다.
살아있는 문서처럼 관리하세요.
출력 폴더
'자기소개'보다 훨씬 간단합니다.
클로드는 세션 중에 생성된 문서, 초안, 분석 결과, 최종 결과물 등 사용자가 실제로 보관할 수 있는 모든 작업물을 이곳에 저장합니다.
Cowork는 여기에 자동으로 저장하지 않습니다.
작업 내용이 보존할 가치가 있을 때 Claude에게 여기에 저장하도록 요청해야 합니다.
세션에서 나온 결과물 중 나중에 참조하거나 재사용하고 싶은 모든 것을 보관하는 파일 캐비닛이라고 생각하면 됩니다.
템플릿 폴더
이것도 간단합니다.
가장 유용하고 재사용하기 좋은 작업 템플릿을 이곳에 저장해 두세요.
일반적으로 이 과정은 다음과 같습니다.
특정 유형의 이메일, 문서 형식, 간략한 구조8 등 특히 잘 만들어진 작업을 세션에서 완료한 후 Claude에게 " 이것을 TEMPLATES 폴더에 템플릿으로 저장해 주세요.
"라고 말합니다.
그러면 Claude는 이를 재사용 가능한 구조로 단순화하여 해당 폴더에 저장합니다.
다음에 비슷한 작업을 해야 할 때는 매번 처음부터 다시 만들 필요 없이 템플릿을 가져와서 시작점으로 활용할 수 있습니다.
글로벌 지침
폴더 설정이 완료되면 모든 것을 연결하는 마지막 구성 단계인 전역 지침 설정이 남았습니다.
이것은 클로드가 코워크에서 모든 작업을 시작하기 전에 항상 읽는 메시지입니다.
작업마다 한 번씩만 읽는 것이 아닙니다.
한 번 작성하면 그 이후로는 항상 백그라운드에서 실행되면서 클로드에게 폴더 구조, 각 파일의 용도, 그리고 파일 사용 방법을 설명해 줍니다.
이 설정이 없으면 클로드는 '내 소개' 폴더가 왜 필요한지, 또는 '템플릿'과 '출력'을 언제 확인해야 하는지 이해하지 못할 수도
있습니다.
설정하려면 Cowork 앱의 설정으로 이동하여 Cowork 섹션을 찾고 " 전역 지침 편집 "을 찾으세요.
여기에 폴더 구조와 파일 용도에 대한 설명을 작성합니다.
명확하고 기능적인 기술 설명서를 작성하세요.
장황한 설명이 아닌 실용적인 정보를 담는 공간입니다.
훌륭한 글로벌 지침은 클로드에게 세 개의 폴더가 무엇인지, ABOUT ME 폴더에 있는 파일에는 어떤 내용이 포함되어
있고 언제 참조해야 하는지, OUTPUTS 폴더에 언제 저장해야 하는지, 그리고 TEMPLATES 폴더에서 가져오거나 TEMPLATES 폴더에 저장해야 하는지를 알려줍니다.
한 번 설정해 놓으면 자주 건드릴 필요가 없습니다.
하지만 이 설정 덕분에 전체 시스템이 서로 연결되지 않은 파일들의 모음이 아니라 하나의 시스템으로 작동하게 되는 것입니다.
Cowork를 일상적으로 실제로 사용하는 방법
모든 설정이 완료되면 일상적인 생활은 수월해집니다.
실질적인 변화를 가져오는 몇 가지 습관은 다음과 같습니다.
- 항상 올바른 폴더와 모델을 선택하세요.
세션을 열 때마다 Claude Cowork 폴더를 가리키고 Opus 4.6을 선택했는지 확인하세요.
5초밖에 걸리지 않지만 매번 중요합니다. - ABOUT ME와 my-company.md 파일을 정기적으로 업데이트하세요.
이 파일들은 정확해야만 유용합니다.
목표가 바뀌었거나, 브랜드 이미지가 발전했거나, 새로운 우선순위가 생겼다면 파일을 업데이트하세요.
오래된 정보는 정보가 없는 것보다 더 나쁩니다. - anti-ai-writing-style.md 파일을 실제로 활용하여 원하는 스타일을 적용하세요.
단순히 저장만 해두고 잊어버리지 마세요.
클로드에게 글을 쓰도록 요청할 때 이 파일을 명시적으로 참조하세요.
"anti-ai-writing-style.md의 규칙을 따라 내 말투로 글을 써 줘"라고 말하는 것이 클로드가 기억하길 바라는 것보다 훨씬 효과적입니다. - 잘 나온 결과물은 템플릿으로 저장하세요.
작업물이 만족스럽게 나올 때마다, 앞으로 비슷한 작업을 다시 해야 할 필요가 있을지 생각해 보세요.
만약 그렇다면, 그 결과물을 템플릿으로 저장해 두세요.
이렇게 '템플릿' 폴더를 꾸준히 관리하면, 최고의 작업 패턴들을 모아놓은 라이브러리가 완성될 것입니다. - 전체 지침이 핵심이 되도록 하세요.
잘 작성된 전체 지침이 있다면 매번 폴더 구조를 다시 설명할 필요가 없을 것입니다.
만약 매번 다시 설명해야 한다면, 지침이 더 명확해야 합니다.
누가 이 기능을 실제로 사용해야 할까요?
Cowork는 개발자가 아닌 사람들을 위해 만들어졌으며, 그 점이 확연히 드러납니다.
코딩도 필요 없고, 폴더 생성 외에는 별도의 설정이 필요 없으며, 기술적인 지식도 전혀 필요하지 않습니다.
하지만 "비개발자"라는 용어는 매우 광범위한 사람들을 포괄하며, Cowork를 가장 효과적으로 활용하는 사람들은 몇 가지 공통점을 가지고 있습니다.
반복 가능한 작업을 하고, 글의 어조와 품질에 신경을 쓰며, 폴더 시스템을 제대로 구축하는 데 초기 한 시간을 투자할 의향이 있다는 것입니다.
이메일, 문서, 보고서, 전략 등 정기적으로 서면 콘텐츠를 작성하고 AI 도구에 맥락을 끊임없이 다시 설명해야 하는 경우, Cowork는 이러한 문제를 직접적으로 해결해 줍니다.
AI를 가볍게 사용하고 자신만의 글쓰기 선호도나 전략적 우선순위를 명확히 정하지 않았다면, AI를 제대로 활용하지 못할 가능성이 큽니다.
시스템의 유용성은 사용자가 입력하는 파일의 질에 달려 있습니다.
저는 클로드 코드 튜닝에 6개월을 투자했습니다.
마침내 제대로 작동하게 된 정확한 설정은 다음과 같습니다.
마침내 제대로 작동하게 된 정확한 설정은 다음과 같습니다.
CLAUDE.md, 하위 에이전트, 후크, 스킬, 작업 트리, 그리고 그 자리를 차지할 만한 다섯 개의 MCP 서버
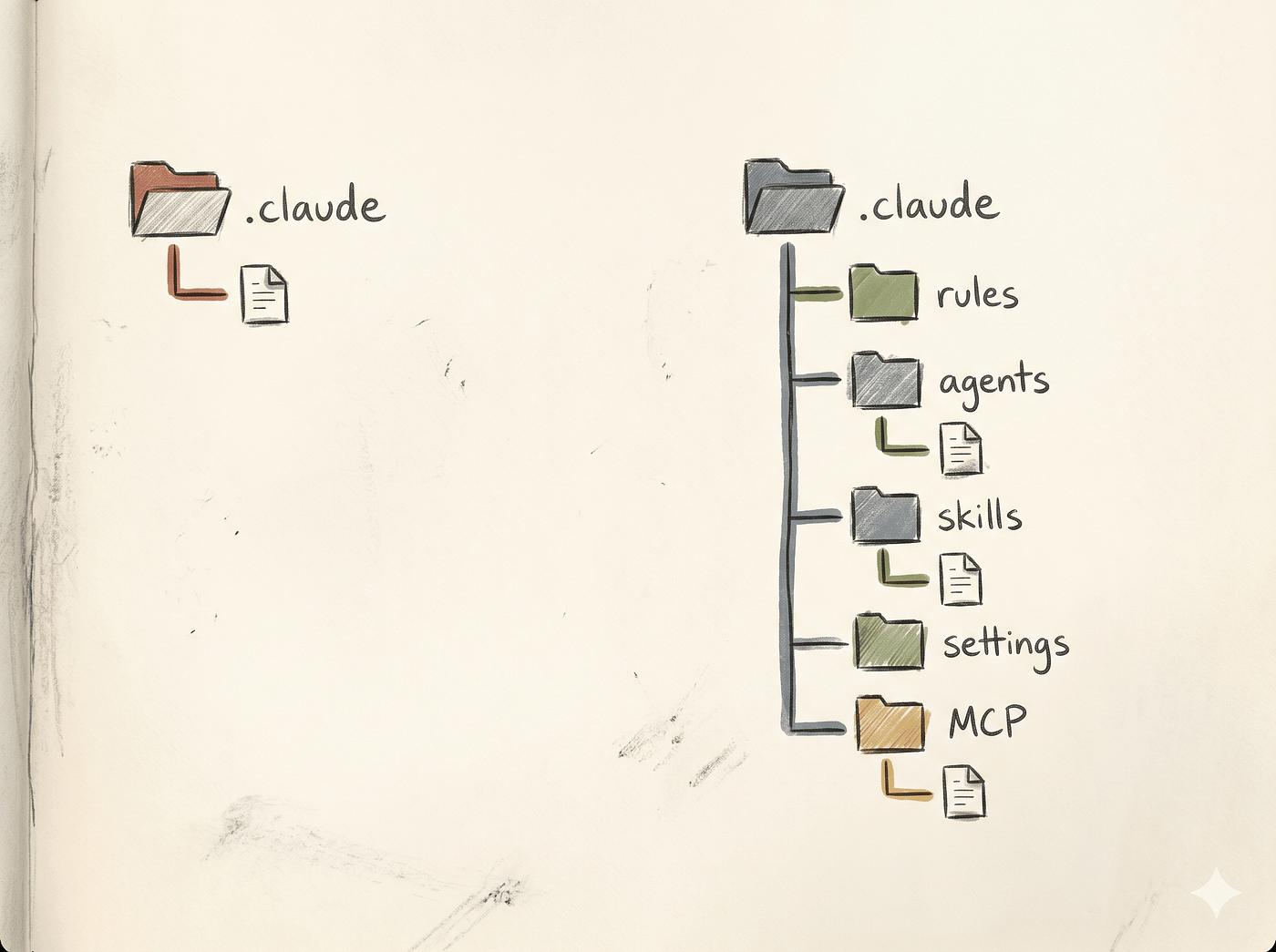
터미널을 엽니다.
메인 AI 프로젝트로 이동합니다.
다음 명령을 실행합니다.tree .claude
현재 Claude Code를 사용하는 대부분의 엔지니어에게 돌아오는 답은 "명령을 찾을 수 없습니다"이거나, 깔끔한 코드를 작성하라는 모호한 지침이 담긴 파일 하나뿐입니다.
물론 그것도 나쁘지 않습니다.
하지만 이는 제품의 약 80%가 버려지는 결과를 초래합니다.
Medium 회원이 아니신가요? 여기에서 전체 기사를 읽어보세요 .
고급 사용자가 구성한 저장소에서 동일한 명령이 어떻게 보이는지는 다음과 같습니다.
.claude/
├── CLAUDE.md
├── rules/
│ ├── langgraph.md
│ ├── retrieval.md
│ ├── tests.md
│ └── python-types.md
├── agents/
│ ├── retrieval-reviewer.md
│ ├── prompt-auditor.md
│ └── eval-runner.md
├── skills/
│ ├── new-rag-eval/
│ │ └── SKILL.md
│ └── claude-pr-checklist/
│ └── SKILL.md
├── settings.json
└── .mcp.json
이 파일들은 모두 길이가 짧습니다.
메인 메모리 파일은 의도적으로 500개 토큰 미만으로 만들었습니다.
각 규칙 파일은 짧은 경로 범위 동작을 나타냅니다.
각 하위 에이전트는 대략 30줄 정도입니다.
설정 파일의 후크 구성은 사전 도구 게이트 하나와 사후 도구
포맷터 하나로 구성됩니다.
서버 구성에는 15개가 아닌 5개의 서버가 있습니다.
두 명의 엔지니어가 똑같은 작업을 맡았다고 상상해 보세요.
기존 검색 서비스에 인용 기반 답변 생성 기능을 추가해야 합니다.
또한, 평가 코드를 작성하고 메인 브랜치에 대한 풀 리퀘스트(PR)를 제출해야 합니다.
한 엔지니어는 빈 폴더를 가지고 있고, 다른 엔지니어는 위와 같은 트리 구조와 헤드리스 모드가 모두 구성된 환경을 가지고 있습니다.
첫 번째 엔지니어는 오후 내내 작업한 기능을 저녁에 배포합니다.
두 번째 엔지니어는 30분 만에 풀 리퀘스트를 제출합니다.
두
엔지니어의 차이는 입력하는 명령어에 있는 것이 아닙니다.
차이는 아무도 설정하지 않은 구성 스택에 있습니다.
메모리 파일부터 시작하세요.
이 파일의 길이가 짧을수록 다른 모든 레이어의 비용이 저렴해지기 때문입니다.

1단계: 메모리 계층 구조
Claude Code는 5단계 메모리 계층 구조를 사용합니다.
홈 디렉터리의 개인 설정, 프로젝트 루트 파일, 경로 범위 규칙, 로컬 미커밋 재정의 및 세션별 자동 메모리 도구 쓰기 작업이 있습니다.
프로젝트 루트 파일은 세션이 시작될 때마다 로드됩니다.
이 파일은 토큰을 영구적으로 소모합니다.
많은 팀들이 엔지니어링 위키의 전체 내용을 이 파일에 저장하고, 핫 캐시가 아닌 벡터 데이터베이스처럼 취급합니다.
제 워크로드에서는 토큰 수가 약 500개를 넘어서면 캐시 적중률이 눈에 띄게 떨어집니다.
새로운 Opus 4.7 토크나이저는 기존 프롬프트를 약 1.0~1.35배 더 많은 토큰으로 매핑하므로, 주변 컨텍스트를 엄격하게 제어하지 않으면 동일한 워크로드에서도 비용이 더 많이 듭니다.
파일 길이는 200줄을 넘지 않도록 하세요.
명령형으로 작성하세요.
"깔끔한 코드를 작성하세요"와 같은 설명적인 제안은 하지 마세요.
"모든 함수에는 TypeScript 타입 어노테이션이 있어야 합니다"와 같이 명확한 규칙을 작성하세요.
모든
코드는 실제로 동작을 변경해야 합니다.
다음은 RAG 서비스에 필요한 최소 파일입니다.
# 인용
검색 및 답변 생성 서비스. LangGraph 기반 파이프라인,
PostgreSQL+pgvector 검색, Gemini 답변 생성, `evals/`
에 있는 평가 도구 . ## 구성 - `services/retrieval/` — 청킹, 임베딩, 재순위 지정, 인용 패키징 - `services/answer/` — 프롬프트 템플릿, 생성기 노드, 가이드라인 - `shared/` — 스키마, 추적, 설정 - `evals/` — 골든 세트, 실행기, 점수 계산
## 빌드 및 테스트
- 설치하다: `uv 동기화`
- 단위 테스트: `uv run pytest -q`
- 평가용 하네스: `uv run python -m evals.run --suite citations`
- Lint + 유형: `uv run ruff format . && uv run mypy .`
## 표준 규칙
- 표준 답변 프롬프트는 `services/answer/prompts/v4.md` 에 있습니다 . 회귀 평가를 위해 고정된 `v3.md`
는 수정하지 마십시오 . - 모든 LLM 출력은 `shared/schemas/answers.py` 에 있는 pydantic 모델로 검증됩니다 . 생성기 노드에서 원시 딕셔너리를 반환하지 마십시오. - 검색은 항상 `citation_id`가 있는 `Chunk` 객체를 반환합니다 . 답변 노드는 해당 ID를 사용하여 인용을 생성해야 합니다.
## 가이드라인 (Claude: 이 가이드라인을 엄격히 준수하십시오) - 동일한 커밋에서 `evals/snapshots/<version>.json` 을 업데이트하지 않고 모델 버전 문자열을 절대 올리지 마십시오
. - `tests/unit/` 내부에 네트워크 호출을 도입하지 마십시오 . `tests/fixtures/` 의 픽스처 와 `tests/fakes/` 의 페이크를 사용하십시오 . - 새로운 최상위 패키지를 추가하는 것보다 기존 모듈을 수정하는 것을 선호하십시오. - 변경 사항이 `services/retrieval/` 에 영향을 미치는 경우 , 계획하기 전에 `.claude/rules/retrieval.md` 를 읽어보세요.
- 함수는 약 40줄 이내로 작성하세요.
함수의 길이가 아닌 책임에 따라 분할하세요.
## PR을 열기 전에 - 평가 도구를 실행하고 변경 사항 결과를 PR 본문에 첨부하세요.
- ` CHANGELOG.md` 의 `
## 미공개` 섹션 을 업데이트하세요 . - `claude-pr-checklist` 스킬을 사용하세요 .
이는 에이전트에게 디렉터리의 정확한 기능을 알려줍니다.
검색 노드와 응답 노드 간의 엄격한 인용 계약을 정의합니다.
또한 모델이 네트워크 모의를 잘못 인식하지 않도록 테스트 스위트에 대한 엄격한 안전장치를 설정합니다.

레이어 2: 경로 범위 규칙
루트 메모리를 체계적으로 관리한 후에도 파일별 명령어를 사용할 수 있습니다.
이러한 명령어는 경로 범위 규칙에 넣으면 됩니다.
이 패턴은 YAML 프런트매터를 사용합니다.
글로브 경로 배열을 정의하면 됩니다.
도구는 일치하는 파일을 만났을 때만 규칙 파일을 로드합니다.
그 외의 경우에는 토큰이 전혀 소모되지 않습니다.
에이전트가 데이터베이스 마이그레이션 스크립트를 편집하는 경우에는
프런트엔드 스타일링 규칙을 읽을 필요가 없습니다.
(참고: paths:공식 스키마 키는 맞지만, 최신 버전에서는 알려진 버그로 인해 해당 키가 누락되는 경우가 있습니다.
globs:규칙이 조용히 무시되는 경우, `<schema_key>` 또는 CSV 형식을 사용하는 것이 더 안정적입니다.
)
다음은 저희 검색 서비스에 사용되는 규칙 파일입니다.
---
이름: 검색 규칙
설명: services/retrieval/** 에 대한 규칙입니다 . Claude가 검색 서비스 내부를 편집 하거나 변경 사항을 계획할 때만 로드 됩니다 . glob : - "services/retrieval/**" - "tests/retrieval/**" --- # 검색 서비스 규칙 ## 청킹 - 모든 문서 수집 에 `shared/chunking.semantic_chunker`를 사용하십시오 . 평가 스냅 샷 을 업데이트 하지 않고 두 번째 청커를 도입 하지 마십시오 . - 청크 크기 목표: 512 토큰, 64 중복. 변경 사항은 ADR 이 필요합니다 . ## 재순위 - 재 순위 인터페이스는 `services/retrieval/reranker.Reranker` 입니다 . 새로운 백엔드는 이를 구현 해야 하며 병렬로 구현해서는 안 됩니다 . - 벡터 검색 에서 상위 50 개 결과 이상 을 재순위 하지 마십시오 . 재순위 지연은 서비스 SLO의 가장 큰 위험 요소입니다.
## 인용 - 검색 에서 반환 되는 모든 `Chunk` 에는 안정적인 ` citation_id`가 있어야 합니다 . - 인용 ID는 `shared/citations.make_citation_id` 에서 생성 됩니다 . 다른 곳에서 ID를 직접 생성 하지 마십시오 . - 답변 노드 는 `citation_id`가 URL에서 안전하다고 가정합니다.
동일한 diff 에서 ` services/answer/citation_packer.py`를 업데이트 하지 않고는 이를 변경 하지 마십시오 . ## 테스트 - 검색 에 대한 단위 테스트는 임베딩 API 를 절대 호출해서는 안 됩니다 . `tests/fakes/embeddings.py` 에 있는 가짜 임 베더를 사용하십시오 . - 통합
테스트는 `tests/retrieval/integration/` 경로에 있으며 , `pytest -m integration` 명령어를 통해 선택적으로 실행할 수 있습니다 .
세 개나 네 개의 짧은 규칙 파일이 하나의 큰 루트 파일보다 낫습니다.
이러한 비용 절감은 대화가 진행될 때마다 누적됩니다.

레이어 3: 평면 모드
대부분의 사람들은 실제 업무 환경에서 계획 모드를 사용하지 않습니다.
그들은 프롬프트를 입력하고 파일이 즉시 변경되는 것을 지켜볼 뿐입니다.
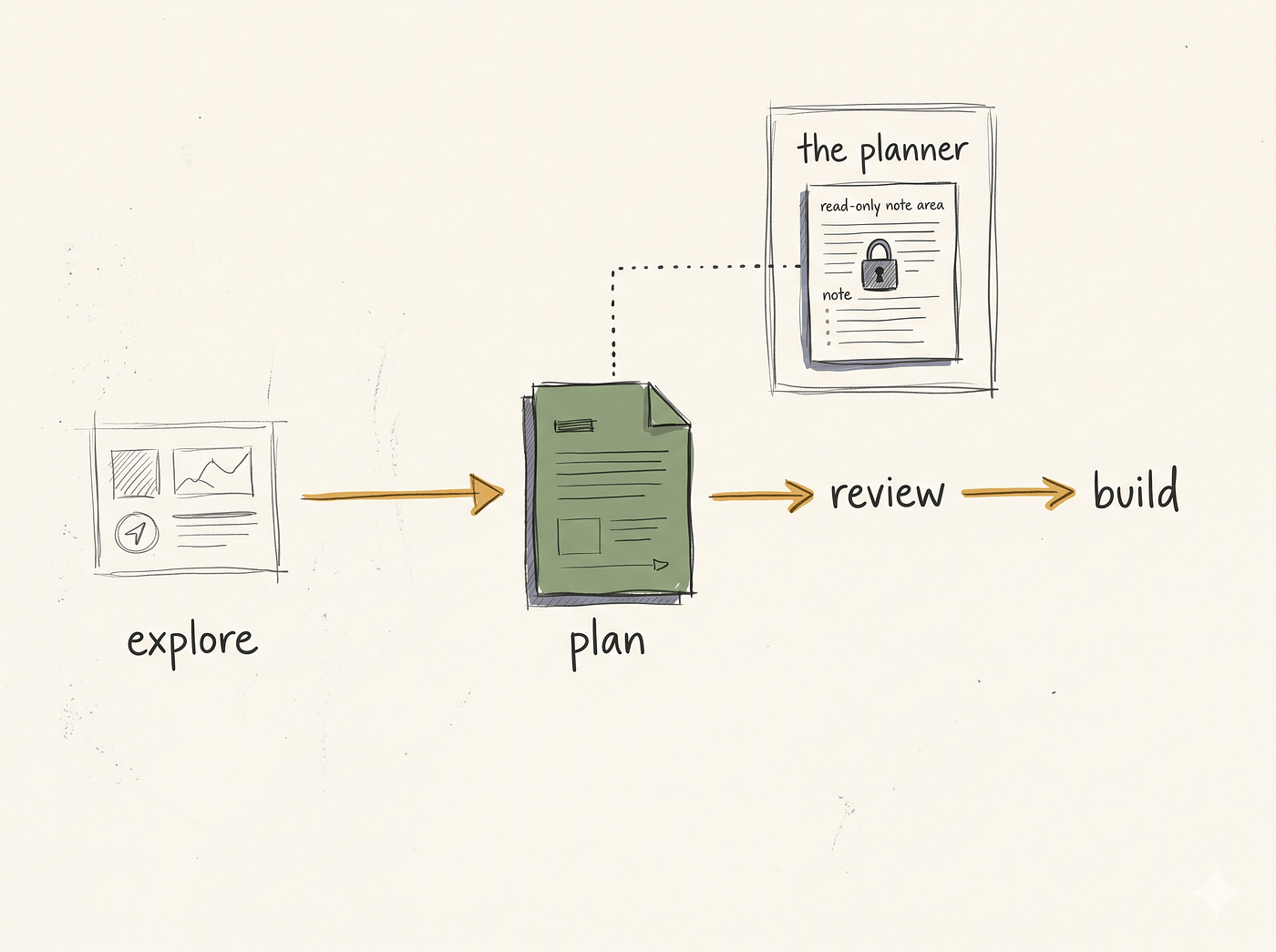
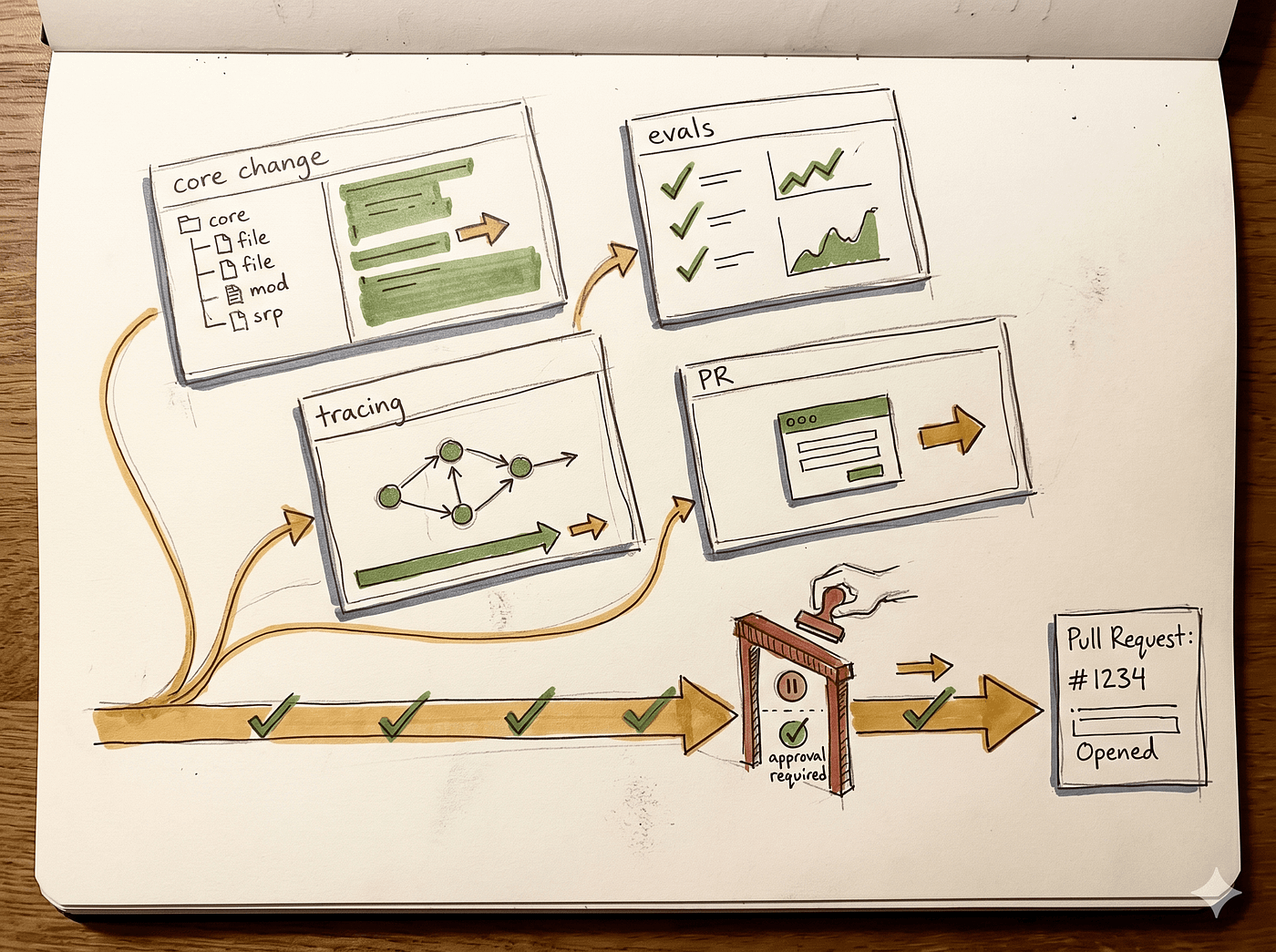
계획 모드는 사고와 실행을 분리합니다.
탐색 과정을 주요 실행 맥락에서 제외하고, 파괴적인 행동이 발생하기 전에 검토하고 수정할 수 있는 명확한 계획 문서를 생성합니다.
Claude Code는 세 가지 계획 단계를 제공합니다.
심플 플랜은 단일 파일에서 짧은 작업을 처리합니다.
비주얼 플랜은 구조가 중요한 여러 파일에 걸친 변경 사항을 계획합니다.
딥 플랜은 여러 서비스에 걸친 변경 사항과 위험 부담이 있는 리팩토링을 처리합니다.
Deep Plan은 위험 평가 및 아키텍처 검토를 위해 하위 에이전트를 사용합니다.
계획 하위 에이전트는 설계상 읽기 전용이며, 쓰기 및 편집 권한이 명시적으로 거부됩니다.
따라서 종속성을 매핑하는 동안 실수로 코드베이스를 변경할 염려가 없습니다.
RAG 서비스 예시에서는 Deep Plan을 사용하여 기존 답변 생성 경로를 추적합니다.
탐색 하위 에이전트는 관련 파일을 간략한 컨텍스트로 가져옵니다.
계획 담당자는 명확한 수정 목록, 평가 추가 사항 목록을 출력하고 풀 요청 설명을 작성합니다.
사용자는 계획을
검토하고 확정합니다.
실제 변경 사항은 계획 모드를 종료한 후에만 적용됩니다.
4단계: 사용자 지정 하위 에이전트
서브에이전트는 해당 도구에서 가장 활용도가 낮은 기능입니다.
이 도구에는 내장된 하위 에이전트가 포함되어 있습니다.
탐색 에이전트는 읽기 전용 코드베이스 검색을 처리합니다.
범용 에이전트는 깔끔한 컨텍스트가 필요한 여러 단계 작업을 처리합니다.
코드 검토자 및 코드 설계자 에이전트는 특화된 역할을 담당합니다.
자주 반복하는 작업이 있거나, 특정 도구 사용에 제한이 있는 역할이 필요하거나, 특정 시스템 메시지가 기본 구성과 충돌하는 경우 사용자 지정 하위 에이전트를 작성합니다.
저희 RAG 서비스 엔지니어는 세 가지 맞춤형 에이전트를 사용합니다.
prompt-auditor는 프롬프트 변경 사항이 규칙에 부합하는지 확인합니다.
eval-runner는 테스트 하네스를 실행하고 구조화된 결과를 생성합니다.
retrieval-reviewer는 도메인별 기준에 따라 재순위화
코드를 검사합니다.
다음은 검색 검토자입니다.
---
이름: retrieval-reviewer
설명: `services/retrieval/` 아래 의 청킹, 재순위 지정 및 인용 계약 회귀 관련 변경 사항을 검토합니다
. 읽기 전용입니다.
검색 코드를 수정하는 PR 을 열기 전에 미리 실행 하세요 . 도구: Read, Grep, Glob, Bash(git diff:*), Bash(uv run pytest:*) 모델: sonnet --- 당신은 citation -rag 저장소 의 검색 서비스 검토자 입니다 . 범위 : - `services/retrieval/**` 아래의 파일 과 해당 테스트 만 검토합니다 . - diff에 나타나 더라도 관련 없는 파일 에는 댓글을 달지 마세요 . 검토 체크 리스트( 순서 대로): 1. 청킹: 변경 사항이 512/64 목표 를 준수 하고 ` shared.chunking.semantic_chunker` 를 단일 진입 점 으로 유지 하는지 확인 합니다 . 2. 재순위화 도구: 재 순위화 도구 인터페이스가 변경된 경우 , 모든 구현이 업데이트 되었는지 , 그리고 상위 k 개 항목 제한이 여전히 50개 이하 인지 확인 합니다.
3. 인용: 반환되는 모든 `Chunk`에는 `shared.citations.make_citation_id` 로 생성된 `citation_id` 가 있어야 합니다 . 수동으로 생성된 ID 는 플래그를 지정합니다 . 4. 테스트: 단위 테스트 에서 새로운 네트워크 호출을 사용하지 않습니다 . 통합 테스트는 `pytest -m integration` 으로 검증합니다 . 5. 평가 영향: 동작이 변경된 경우 , 동일한 커밋 에서 `evals/snapshots/*.json` 파일이 다시 생성 되었는지 확인 합니다 .
출력 형식 :
- 간략한 "판결" (통과 / 변경 필요 / 방해 요소). - 발견 사항 목록 ( 각각 파일 경로 및 한 줄 수정 사항 포함 ) . - 관련 없는 리팩토링 제안은 삼가 주세요 .
프론트매터를 살펴보세요.
tools 라인은 읽기 권한과 제한된 범위의 bash 실행 권한만 부여하는 좁은 허용 목록입니다.
model 라인은 에이전트를 Sonnet으로 다운그레이드합니다.
메인 루프는 어려운 추론을 위해 비용이 많이 드는 모델을 계속 사용하고, 하위 에이전트는
백그라운드에서 저렴하게 실행됩니다.
5단계: 기술
스킬 패키지를 사용하면 워크플로를 이름으로 실행할 수 있습니다.
스킬은 YAML 프런트매터가 포함된 마크다운 파일이 들어 있는 폴더입니다.
파이썬 스크립트, bash 명령어, 테스트 픽스처 등을 포함할 수 있습니다.
이 아키텍처는 점진적 공개 방식을 기반으로 합니다.
메타데이터는 세션 시작 시 로드되고, 실제 명령어는 스킬을 실행할 때만 로드됩니다.
번들 리소스는 에이전트가 참조할 때만 로드되므로, 스킬을 50개 설치하더라도 주변 토큰 비용을 낮게 유지할 수 있습니다.
저희는 라는 스킬을 개발했습니다 new-rag-eval. 이 스킬은 템플릿에서 새로운 평가 사례를 생성하고, 해당 사례를 하네스에 연결하고, 현재 파이프라인을 대상으로 실행한 후, 결과 요약을 작성합니다.
---
이름: new -rag-eval
설명: 골든
예제 에서 새로운 RAG 평가 케이스를 지원 하고 , 이를 평가 하네스 에 연결하고 , 현재 파이프라인에 대해 실행하고 , 결과 요약 을 작성합니다 . 사용자 가 " …에 대한 평가를 추가해 주세요" 또는 "이 회귀 오류를 평가로 커버해 주세요" 라고 요청할 때 사용합니다 . 허용 도구: 읽기, 쓰기 , 편집, Bash(uv run:*), Bash(git add:*) --- # new-rag-eval ## 사용 시점 사용자 가 `evals/suites/citations/` 에 새로운 평가 케이스 를 추가 하거나 평가 하네스 에서 회귀 오류를 재현 하려는 경우 트리거 됩니다 . ## 먼저 수집할 입력 1. 쿼리 에 대한 자연어 설명 . 2. 예상되는 인용 ID ( 또는 예상 되는 답변 텍스트 ) . 3. 선택 사항: 프로덕션 에서 실패한 추적 ID . ## 단계 1. `evals/templates/case.json`을 읽 습니다 . 이것은 케이스 템플릿 입니다 . 2 . 1. 사용자 에게 쿼리 , 예상 인용문 및 메모 를 입력받습니다 . 2. 템플릿 을 사용하여 `evals/suites/citations/<slug>.json` 에
새 케이스
파일을 작성
합니다 .
슬러그 는 쿼리 의 kebab-case 입니다 . 3. 이 케이스에 대해서만 실행 도구를 실행합니다.
`uv run python -m evals.run --suite citations --case <slug>` 4. JSON 출력 을 파싱 합니다 .
`evals/out/<slug>.json` 파일을 확인합니다.
요약 :
- 통과 / 실패
- 근거 있는 인용 비율
- 근거 없는 주장 비율
- 새로운 지연 시간 이상치 6. 실패하는 경우 , 케이스 파일 의 ` notes :` 섹션에 "오늘 실패할 것으로 예상되는 이유"에 대한 간략한 메모를 추가합니다.
7. ` git add evals / suites / citations / <slug>.json` 명령 으로 새 케이스를 스테이징 합니다 . ## 하지 말아야 할 사항 - `evals/ templates /case.json` 파일 을 수정 하지 마십시오 . - 다른 평가 스위트를 건드리지 마십시오 . - 이 스킬 에서 PR 을 열지 마십시오 . PR 흐름 은 ` claude-pr-checklist` 스킬 에 있습니다 .
허용된 도구는 스킬의 기능을 결정론적으로 제한합니다.
평가 스크립트와 스테이징 파일을 실행할 수 있지만, 프로덕션 환경에 배포할 수는 없습니다.
또한, 풀 리퀘스트 흐름을 위해 에이전트가 두 번째 스킬을 사용하도록 지정합니다.
6단계: 훅과 결정론
훅(Hooks)은 에이전트를 더 적은 관리자만으로도 안전하게 실행할 수 있도록 해줍니다.
훅은 확률 시스템에 결정론적 안전장치를 추가합니다.
설정 파일에서 후크를 구성할 수 있습니다.
이벤트에는 세션 시작, 사용자 프롬프트 제출 및 도구 사용이 포함됩니다.
2026년 4월 릴리스에서는 안전 분류기 거부에 대한 특정 후크가 추가되어 거부된 작업을 감사할 수 있습니다.
가장 중요한 추가 기능은 지연 권한(Deferred Permissions)입니다.
이제 사전 도구 후크를 통해 에이전트 실행을 헤드리스 모드에서 일시 중지하는 지연 결정을 반환할 수 있습니다.
사용자는 세션을 검사하고 별도의 시간 내에 작업을 승인할 수 있습니다.
에이전트는
중단된 지점에서 정확히 다시 실행됩니다.
지연 권한 기능이 도입되기 전에는 메인 브랜치에 푸시해야 하는 야간 실행 작업이 --dangerously-skip-permissions새벽 3시에 실패하거나 아예 실행되지 않는 경우가 있었습니다.
RAG 서비스에 두 가지 실용적인 훅을 구성합니다.
post-tool 훅은 모든 쓰기 작업 후에 코드 포맷터를 조용히 실행합니다.
pre-tool 훅은 메인 브랜치를 대상으로 하는 모든 git push를 지연시킵니다.
{
"hooks" : {
"PreToolUse" :
[
{
"matcher" : "Bash" ,
"hooks" : [
{
"type" : "command" ,
"command" : ".claude/hooks/gate_git_push.sh"
}
]
}
] ,
"PostToolUse" : [
{
"matcher" : "Write|Edit|MultiEdit" ,
"hooks" : [
{
"type" : "command" ,
"command" : "uv run ruff format $CLAUDE_TOOL_FILE_PATH >/dev/null 2>&1 || true"
}
]
}
] ,
"PermissionDenied" : [
{
"hooks" : [
{
"type" : "command" ,
"command"
: "jq -c . >> .claude/logs/denied.jsonl"
}
]
}
]
}
}
다음은 해당 게이트에 대한 보조 셸 스크립트입니다.
#!/usr/bin/env bash
# main을 대상으로 하는 모든 `git push`를 지연시킵니다.
세션이 일시 중지됩니다.
사람이
별도로 승인하면 `claude --resume`를 통해 에이전트가 다시 시작됩니다.
set -euo pipefail
payload= " $(cat) "
cmd= " $(printf '%s' " $payload " | jq -r '.tool_input.command // empty') "
case " $cmd " in
* "git push" * "origin main" *|* "git
push" * " main" *)
jq -nc '{
"permissionDecision": "defer",
"reason": "main으로 푸시하려면 사람의 승인이 필요합니다.
"
}'
;;
*)
jq -nc '{"permissionDecision": "allow"}'
;;
esac
포스트 툴 훅은 일부러 단순하게 만들어졌습니다.
한 줄짜리 서식 지정 훅은 투자 대비 최고의 효율을 제공합니다.
에이전트가 지저분한 파일을 작성하면 훅이 린터를 실행합니다.
이렇게 하면 다음 실행 전에 파일이 깔끔해집니다.
에이전트는 자신의 잘못된 들여쓰기
때문에 혼란스러워하는 일이 없습니다.
7계층: 서버 스택
모델 컨텍스트 프로토콜은 에이전트를 외부 도구에 연결합니다.
많은 개발자들이 서버를 15개나 설치하고 나서 에이전트가 혼란스러워하는 이유를 궁금해합니다.
설치하는 모든 서버에는 도구 스키마가 포함되어 있습니다.
이러한 스키마는 매 턴마다 컨텍스트 토큰을 소모합니다.
Anthropic의 도구 검색 문서에 따르면, 지연 로딩을 사용하지 않을 경우 50개의 도구가 턴당 10,000~20,000개의 토큰을 소모할 수 있습니다.
도구
검색의 지연 로딩을 사용하면 소모되는 토큰의 양이 약 85% 감소하지만, 서버 수를 줄이는 것이 여전히 더 나은 전략입니다.
본격적인 엔지니어링 환경을 구축하려면 서버가 정확히 5대 필요합니다.
영구 세션 메모리를 갖춘 코드 그래프 서버, 브랜치 및 커밋 관리를 위한 GitHub 서버, 디렉터리 간 접근을 위한 파일 시스템 서버, 최신 문서를 검색할 수 있는 웹 검색 서버, 그리고 버전별 라이브러리 풀링을 위한 전용 컨텍스트 서버가 필요합니다.
{
"mcpServers" : {
"vexp" : {
"command" : "npx" ,
"args" : [ "-y" , "@vexp/mcp-server@latest" ] ,
"env" :
{
"VEXP_PROJECT" : "citation-rag" ,
"VEXP_MEMORY_DIR" : ".vexp"
}
} ,
"github" : {
"command" : "npx" ,
"args" : [ "-y"
, "@modelcontextprotocol/server-github" ] ,
"env" : {
"GITHUB_PERSONAL_ACCESS_TOKEN" : "${GITHUB_TOKEN}"
}
} ,
"filesystem" : {
"command" : "npx" ,
"args" : [
"-y" ,
"@modelcontextprotocol/server-filesystem" ,
"${HOME}/code/citation-rag" ,
"${HOME}/code/shared-prompts"
]
} ,
"brave-search" : {
"command" : "npx" ,
"args" : [ "-y" , "@modelcontextprotocol/server-brave-search" ] ,
"env" : { "BRAVE_API_KEY" : "${BRAVE_API_KEY}" }
} ,
"context7" : {
"command" : "npx" ,
"args" :
[ "-y" , "@upstash/context7-mcp@latest" ]
}
}
}
만약 여러분이 프로덕션 환경에 직접 쿼리를 보내는 AI 엔지니어라면 데이터베이스용 서버를 하나 더 추가하는 것을 고려해 볼 수 있습니다.
하지만 서버 목록은 최소한으로 유지하는 것이 좋습니다.
vexpvexp에서 공개한 벤치마크에 따르면, 서버 하나만으로도 장시간 실행되는 에이전트 환경에서 토큰 사용량을 65~70%까지 줄일 수 있습니다.
2026년 4월 릴리스에는 문서화 도구에서 찾아볼 수 있는 미묘한 서버 측 기능이 추가되었습니다.
이제 서버는 anthropic/maxResultSizeChars도구의 _meta필드에 주석을 설정할 수 있습니다.
이를 통해 대규모 라이브러리 문서를 디스크에서 읽어오는 대신 인라인으로 가져올 수 있으므로 기존의 파일 쓰기 방식을 완전히 우회할 수 있습니다.
8단계: 병렬 작업 트리 및 헤드리스 자동화
워크트리를 사용하면 상담원이 입력을 마칠 때까지 기다리는 시간을 줄일 수 있습니다.
명령어를 한 번 실행하면 도구가 브랜치, 작업 트리, 그리고 격리된 세션을 생성합니다.
각 작업 트리는 자체적인 편집기 상태와 실행 중인 프로세스를 유지하며, 병렬 창에서 관리할 수 있습니다.
저희 엔지니어는 인용 작업을 병렬화합니다.
첫 번째 창에서는 핵심 생성 변경 사항을 구현하고, 두 번째 창에서는 평가 기능을 재작성합니다.
세 번째 창에서는 새로운 검색 경로에 추적 기능을 추가하고, 네 번째 창에서는 풀 리퀘스트 초안을 작성합니다.
각 창은
자체 컨텍스트를 사용하여 별도의 세션에서 실행됩니다.
작업이 겹치면 편집 내용도 겹치지만, 한 창에서는 평가를, 다른 창에서는 핵심 로직을 담당하는 것처럼 작업을 명확한 영역으로 구분하면 실제로 병합 충돌이 발생하는 경우는 드뭅니다.
마지막으로 헤드리스 모드가 있습니다.
에이전트를 지속적 통합 파이프라인에서 비대화형으로 실행합니다.
특정 도구를 화이트리스트에 추가하고 로컬 구성을 제거하여 재현 가능한 동작을 구현합니다.
다음은 GitHub Actions에서 실행되는 야간 평가 작업입니다.
이름: claude-nightly-evals
실행 시간:
스케줄: [{ cron: "0 7 * * *" }]
워크플로우 디스패치:
작업:
run-evals-and-open-pr:
실행 환경: ubuntu-latest
권한:
내용: 쓰기
풀 리퀘스트: 쓰기
환경 변수:
ANTHROPIC_API_KEY:
${{ secrets.ANTHROPIC_API_KEY
}}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
단계:
- 사용: actions/checkout@v4
- 사용: astral-sh/setup-uv@v3
- 실행: uv sync
- 이름: Claude 코드 설치 실행: npm i -g @anthropic-ai/claude-code@latest - 이름: 야간 평가 실행 + PR 초안 작성 (헤드리스) ID: claude 실행: | set -o pipefail
claude -p \ --bare \ --output-format stream-json \ --allowedTools "Bash(uv run:*),Read,Grep,Glob,Write,Edit,mcp__github__*" \ --append-system-prompt "You are the nightly eval runner. \ Run the citations eval suite. If regressions appear, \ open a draft PR with a fix attempt and the eval diff." \ "Run: uv run python -m evals.run --suite citations. \ If any case regresses, implement the minimal fix and open \ a draft PR against main
via the GitHub MCP." \ | tee claude.ndjson if grep -q '"permissionDecision":"defer"' claude.ndjson; 그런 다음 "deferred=true" >> "$GITHUB_OUTPUT"를 출력합니다.
fi - 이름: 메인 푸시 시 실행이 지연된 경우 재개 합니다.
if: steps.claude.outputs.deferred == 'true' run: | SESSION_ID="$(jq -r 'select(.type=="deferred") | .session_id' \ claude.ndjson | head -n1)" claude --resume "$SESSION_ID" \ --append-system-prompt "승인되었습니다.
계속하십시오." \ --output-format stream-json
허용된 도구들은 이전에 구축한 후크와 상호 작용합니다.
작업은 평가를 실행하고, 수정 사항 초안을 작성한 후 메인 브랜치로 푸시를 시도합니다.
후크는 푸시를 감지하고 승인 요청을 연기합니다.
파이프라인은 JSON 로그를 파싱하고 출력 변수를 설정한 후 일시
중지합니다.
담당자가 구조화된 로그를 검토하고 승인합니다.
재개 명령은 정확한 세션 ID를 가져와 작업을 완료합니다.
리플레이
우리는 스택을 가지고 있습니다.
실제 제품을 사용하여 90분 배송 과정을 살펴보겠습니다.
세션이 시작됩니다.
엔지니어가 프로젝트를 열고 피처 작업 트리를 생성합니다.
메모리 파일과 규칙이 자동으로 로드됩니다.
다섯 대의 서버가 연결됩니다.
엔지니어는 심층 계획 모드로 진입합니다.
탐색 하위 에이전트는 현재 검색 경로를 매핑하고 계획기는 구체적인 문서를 출력합니다.
## 구현 계획: 인용 기반 생성
1. **`services/retrieval/search.py` 수정** : `Chunk` 객체가 `shared.citations.make_citation_id`를 통해 `citation_id`를 첨부하도록 합니다 . 2. **`services/answer/generator.py` 업데이트** : Gemini 시스템 프롬프트 컨텍스트 블록에 `[Source: {citation_id}]`를 삽입합니다.
3. **평가 도구 생성** : 엄격한 인용 형식 검증을 위해 `evals/suites/citations/defective-charger.json` 파일을 추가합니다.
엔지니어는 계획을 검토하고 확정합니다.
구현은 메인 작업 트리에서 실행됩니다.
에이전트가 검색 로직 수정을 완료하면 retrieval-reviewer하위 에이전트를 호출합니다.
하위 에이전트는 경로 범위 규칙에 따라 심각한 차단 오류를 반환합니다.
**판결: 차단**
* `services/retrieval/search.py` : 42번째 줄에서 인용 ID에 대한 UUID를 직접 생성했습니다.
규칙 `.claude/rules/retrieval.md` 에는 `shared.citations.make_citation_id`가 필요합니다 .
* `tests/retrieval/test_search.py` : 새 데이터베이스 테스트에서 `@pytest.markm.integration` 이 누락되었습니다.
에이전트는 수동으로 생성된 ID와 누락된 데코레이터를 수정합니다.
포스트 툴 훅은 모든 쓰기 작업 후 서식을 깔끔하게 유지합니다.
병렬 작업이 시작됩니다.
두 번째 작업 트리는 new-rag-eval스킬을 사용하여 평가를 다시 작성합니다.
헤드리스 실행은 최종 평가 하네스를 실행하고 차이점을 생성합니다.
{
"suite" : "citations" ,
"cases_run" : 45 ,
"grounded_citation_rate" : { "previous"
: 0.82 , "current" : 0.98 , "delta" : "+0.16" } ,
"unsupported_claims" : { "previous" : 12 , "current" : 0 , "delta" : "-12" } ,
"status" : "PASS"
}
승인 지연으로 푸시가 일시 중지됩니다.
엔지니어가 승인하면 전체 변경 사항과 평가 차이점이 첨부된 풀 리퀘스트가 GitHub 서버를 통해 열립니다.
이는 작업 범위가 명확하게 정의되어 있고 필요한 기술 스택이 이미 구축되어 있다는 가정하에 가능한 이야기입니다.
처음 구축할 때는 오후 시간 정도면 충분하지만, 그 이후의 작업은 그 시간이 훨씬 더 오래 걸립니다.
바닥과 천장
이 설정을 순식간에 망칠 수 있습니다.
대용량 메모리 파일을 작성하거나 서버를 15대나 설치하지 마십시오. 도구 스키마는 무료가 아닙니다.
하위 에이전트가 속한 메인 세션을 사용하지 마십시오. 탐색 및 검토는 별도의 컨텍스트에서 수행해야 합니다.
모든 것을 다 할 수 없다면 최소한 최소한의 것은 해야 합니다.
프로젝트 루트에 간단한 명령형 메모리 파일을 만드세요.
가장 자주 접근하는 디렉터리에 대해 경로 범위 규칙 파일 두 개를 작성하세요.
서식 지정 후크 하나를 추가하세요.
저장소, 파일 시스템,
라이브러리 문서화를 위한 서버 세 개를 설치하세요.
틀릴 위험이 있는 모든 작업에는 반드시 계획 모드를 사용하세요.
작업이 계속 반복될 때는 하위 에이전트를 추가하세요.
워크플로가 안정화되어 패키징할 수 있을 때는 스킬을 추가하세요.
한 시간에 두 번 이상 브랜치를 전환하는 경우가 있다면 작업 트리를 추가하세요.
잠자는 동안에도 에이전트가 코드를 배포하도록 하려면 헤드리스
모드를 추가하세요.
이제 저희 에이전트는 코드베이스를 완벽하게 탐색할 수 있습니다.
하지만 컨텍스트 창에 오래된 관찰 데이터가 서서히 쌓이는 장기 실행 작업에서는 여전히 어려움을 겪고 있습니다.
다음 게시물에서는 고급 기능을 다루면서 컨텍스트 누적, 압축 및 도구 결과 삭제를
통해 장기 실행 에이전트가 메모리 과부하에 시달리지 않도록 하는 방법을 살펴보겠습니다.
스택은 워크플로입니다.
워크플로는 곱셈기입니다.
프롬프트는 마지막 5%에 불과합니다.